Four Reasons Presto is the Best SQL-on-Hadoop (That You Haven’t Heard Of)
Four Reasons Presto is the Best SQL-on-Hadoop (That You Haven’t Heard Of)
Four Reasons Presto is the Best SQL-on-Hadoop (That You Haven’t Heard Of)
Presto is an in-memory distributed SQL query engine developed by Facebook that has been open-sourced since November 2013. Presto has a number of key advantages over other SQL-on-Hadoop engines, yet these benefits are not widely recognized or understood.
Reason #1: Presto is Plenty Fast
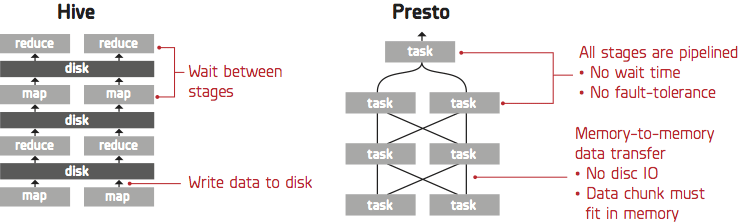
Unlike MapReduce, which was designed for very high throughput at the expense of mid-to-high latency, Presto is designed to be interactive. For example, our benchmarking shows that running the query “SELECT min(id),count(*) FROM table WHERE column = ‘string’ GROUP BY id ORDER BY count DESC” against 50-100TB of data in Treasure Data’s environment takes approximately 20 seconds. This is not a surprise, considering that Presto was designed to be able to handle Facebook’s analytic workloads.
MapReduce operates on a “pull” model and pulls data from the preceding tasks. Presto follows the “push” model, which processes a SQL query using multiple stages running concurrently. An upstream stage receives data from its downstream stages, so the intermediate data can be passed directly, thus making the query significantly faster.
Reason #2: Presto Supports ANSI-SQL and Postgres ODBC/JDBC Connectivity
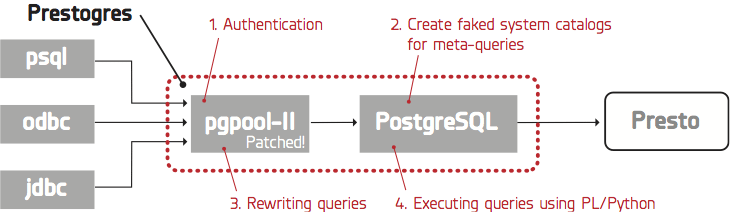
SQL-on-Hadoop is still in its nascent phase, and as a result, standard driver support such as ODBC and JDBC is still unstable. However, for Presto there is open source middleware called Prestogres that allows the user to use Postgres ODBC/JDBC drivers to connect to Presto. This means you can leverage your existing Postgres assets such as ODBC/JDBC drivers and query templates.
Reason #3: Presto has PostgreSQL-like Window Functions (and more)
PostgreSQL is quickly establishing itself as the leading free analytics database for “medium” sized data due to its analytic functions, especially window functions. Here is the good news: Presto has all 11 window functions that PostgreSQL has.
To view the general-purpose Window functions of PostgreSQL and Presto, click here.
Reason #4: Presto is Not Glued to HDFS
To be sure, Presto isn’t the only SQL-on-Hadoop, but it very well may be the only SQL-on-and-off-Hadoop at present. Because its excellent design separates the query engine layer (Presto) from the standard Hadoop storage layer (HDFS, etc.) and provides a clean interface between them via “connectors,” Presto gives data engineers and architects tremendous flexibility. Treasure Data took advantage of this flexibility to integrate Presto into Treasure Plazma, our custom distributed, columnar storage layer.
Treasure Data includes several embedded analytics engines, including Presto. Because Presto can be run against any storage layer with a connector, we have built a connector for our efficient Treasure Plazma columnar data store, so Presto can run against it. This design decouples compute from storage, allowing Treasure Data to serve a wide range of query workloads for its global customer base.
Learn more about the analytics engines within Treasure Data here.