Treasure Data Python Client; MySQL, PostgreSQL, and Jira connectors; and more
Treasure Data Python Client; MySQL, PostgreSQL, and Jira connectors; and more
Treasure Data Python Client; MySQL, PostgreSQL, and Jira connectors; and more
Treasure Data has made Python the glue for your end-to-end data analytics pipeline. Now it’s easier than ever to link your data science toolkit directly to a robust and infinitely scalable data storage and analytics pipeline in the cloud and be up and running in minutes!
Maybe you’re brand new to data science, are a manager looking for a fast cycle time, or are an experienced old hand at Data Science. In addition to connecting directly to staples like Jupyter and Pandas, you can now pipe in data directly from MySQL, Postgre SQL and Jira, as well as engage Treasure Data Agent directly from Python. Whatever your skill level, you can leave the analytics infrastructure to us while you focus on your data!
This release also includes a few key Presto enhancements, and a new JDBC Driver.
Treasure Data Client for Python
Treasure Data and Pandas Connector
Data Connectors for MySQL, PostgreSQL and Jira
Presto! New improvements + JDBC driver update
Treasure Data Client for Python
Treasure Data is now supported by an API library for Python. From Python 2.7 or greater, 3.3 or greater or PyPy, you can now list jobs, run jobs, import data (including bulk import), and kick off Presto or Hive queries:
import pandas
import tdclient
def on_waiting(cursor):
print(cursor.job_status())
with tdclient.connect(db="sample_datasets", type="presto", wait_callback=on_waiting) as td:
data = pandas.read_sql("SELECT symbol, COUNT(1) AS c FROM nasdaq GROUP BY symbol", td)
print(repr(data))
Get the library from Github.
Treasure Data and Pandas Connector
With Treasure Data, you can now munge data and perform analytics directly from the powerhouse library Pandas. As detailed in this blogpost, you can run Treasure Data queries and analyze your data right from Pandas and Jupyter (formerly iPython notebook).
Data Connectors for MySQL, PostgreSQL and Jira
These brand new connectors enable you to link up Treasure Data to import data from MySQL, PostgreSQL and Jira directly.
Setting up each connector works similarly. First, you need to ensure that you’re running the latest Treasure Data Toolbelt:
$ td –version
0.11.10
Next you should prepare a seed.yml – basically a Ruby configuration file containing your access information to the respective service. Here’s the one for the MySQL connector:
config:  :in: type: mysql host: mysql_host_name port: 3306 user: test_user password: test_password database: test_database table: test_table select: "*" out: mode: replace
Treasure Data uses artificial intelligence to guess the file format you’ll be importing from, but you must prompt it first:
$ td connector:guess seed.yml -o load.yml
Then, you can preview how the system will parse the file:
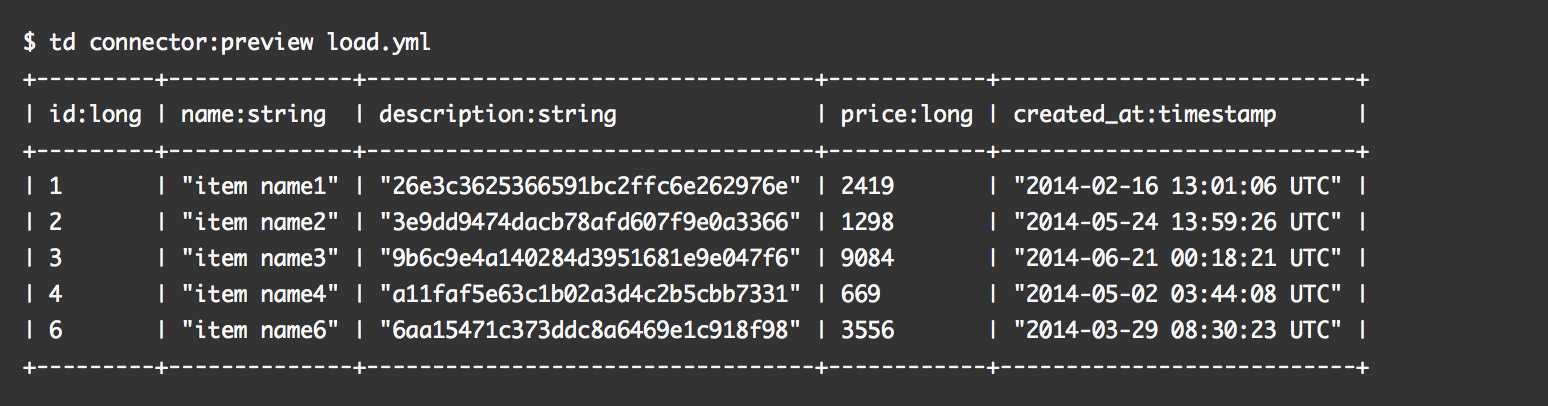
Finally, import jobs can be scheduled or run as standalone.

Read the connector docs for MySQL, PostgreSQL and Jira to learn more.
Presto! New improvements + JDBC driver update
JDBC Driver v0.3.4 supports a new “SELECT 1” query used by a number of BI tools.
Presto engine also contains a number of significant improvements, including a new “black hole” connector that writes a session’s metadata to memory (like a /dev/null device on Unix) along with some key performance optimizations. This version also iteratively contains the patches supporting 0.107 and 0.106 Presto versions.