5 Tips to Optimize Fluentd Performance
5 Tips to Optimize Fluentd Performance
5 Tips to Optimize Fluentd Performance
We’ve recently gotten quite a few questions about how to optimize Fluentd performance when there is an extremely high volume of incoming logs. Kazuki Ohta presents 5 tips to optimize fluentd performance. They are:
- Use td-agent2, not td-agent1.
- Use ‘num_threads’ option.
- Avoid extra computations.
- Use external ‘gzip’ command for TD/S3.
- Use multi-process.
Use td-agent2, not td-agent1
Back in April we released td-agent2, a better and more reliable version of td-agent that benefits from two performance optimizations:
Ruby
Ruby was upgraded from 1.9 to 2.1, which boosts the performance.
MessagePack
We’ve rewritten the Ruby supporting MessagePack, the highly efficient binary serialization format used internally. (MessagePack was invented by Treasure Data‘s co-founder Sadayuki Furuhashi).
Specifically, we’ve introduced an intelligent buffer management system, which yields higher performance with a lower memory footprint.The chart below contains performance comparisons for various serialization libraries, including both new and old MessagePack Ruby, using a Twitter JSON data set.
As you can see, the new version is 4 times faster for serialization and 10 times faster for deserialization.
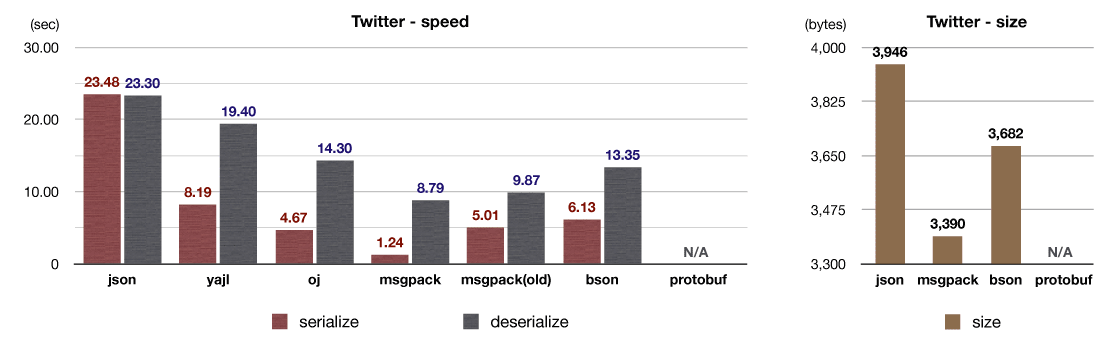
We recommend that every user upgrade to td-agent2 as soon as possible.
Use ‘num_threads’ option
If the destination for your logs is a remote storage or service, adding a ‘num_threads’ option will parallelize your outputs (the default is 1). This parameter is available for all output plugins
<match test> type output_plugin num_threads 8 ... </match>
Use external gzip command for S3/TD
Ruby has GIL (Global Interpreter Lock), which allows only one thread to execute at a time. While I/O tasks can be multiplexed, CPU-intensive tasks will block other jobs. One of the CPU-intensive tasks in Fluentd is compression. The new version of S3/Treasure Data plugin allows compression outside of the Fluentd process, using gzip. This frees up the Ruby interpreter while allowing Fluentd to process other tasks.
While not a perfect solution to leverage multiple CPU cores, this can be effective for most Fluentd deployments. As before, you can run this with ‘num_threads’ option as well.
# S3 <match ...> type s3 store_as gzip_command num_threads 8 ... </match> # Treasure Data <match ...> type tdlog use_gzip_command num_threads 8 ... </match>
Avoid extra computations
This is more like a general recommendation, but it’s always better not to have extra computation inside Fluentd. Fluentd is flexible to do quite a bit internally, but adding too much logic to Fluentd’s configuration file makes it difficult to read and maintain, while making it also less robust. The configuration file should be as simple as possible.
Use multi-process
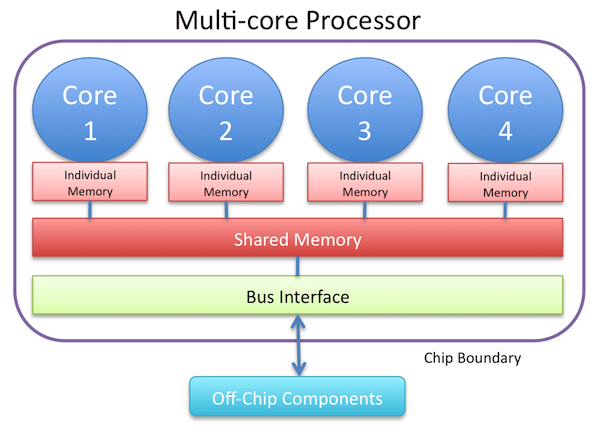
If your fluentd process is still consuming 100% CPU with the above techniques, you can use the Multiprocess input plugin. This plugin allows your Fluentd instance to spawn multiple child processes. While this requires additional configuration, it works quite well when you have a lot of CPU cores in the node.
Conclusion
We’ve just gone through 5 different steps to optimize Fluentd performance. If you have any further questions, please ask us at Fluentd Google Groups. Happy logging!