How a “Big Six” Studio Quadrupled Data Analysis Speed with this One Simple Technique
How a “Big Six” Studio Quadrupled Data Analysis Speed with this One Simple Technique
How a “Big Six” Studio Quadrupled Data Analysis Speed with this One Simple Technique
A major entertainment company speeded up query time from hours to minutes by a simple technique: replacing COUNT(DISTINCT x) with APPROX_DISTINCT(x).
Why Should I Care?
COUNT(DISTINCT x) and APPROX_DISTINCT(x) are both used to count the number of unique elements in a data, such as unique users or events. For instance, you might want to count how many distinct users accessed your online gaming site per day, but do not want to double-count the customers who accessed the game at separate times on the same day. Or you see that your e-commerce website had 10 million hits today, but you want to know how many distinct shoppers had been there. As you can see, you probably want to count unique users or events often – the aforementioned entertainment company uses COUNT(DISTINCT x) in its queries nearly 1,000 times a day. Any improvement in efficiency on such queries could save substantial time (and money).
What is the Difference Between APPROX_DISTINCT(x) and COUNT(DISTINCT x)?
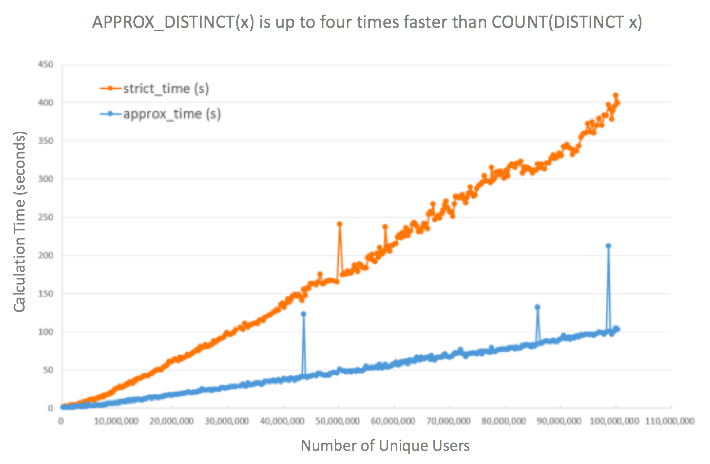
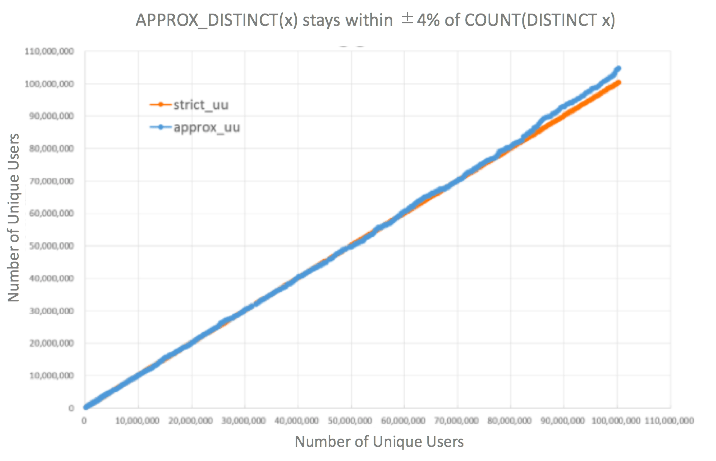
APPROX_DISTINCT provides a close estimate of the value returned by COUNT(DISTINCT) in far less computing time. For COUNT(DISTINCT x), the amount of processing time required for counting grows proportionally to the number of unique elements (also known as cardinality) in your data. That becomes a problem when your data is very large! On the other hand, APPROX_DISTINCT(x) uses an algorithm called HyperLogLog to estimate cardinality in a fraction of the time needed for an exact count. For example, to count 100 million unique users, APPROX_DISTINCT(x) can estimate COUNT(DISTINCT x) within ±4% error rate at a quarter of the calculation time, according to BrainPad Inc.
Why Should I Use APPROX_DISTINCT(x)?
You can get much faster time to insight (and lower computing costs) by trading off a bit of precision, while still having high confidence about the accuracy of your estimate.
When Should I Use APPROX_DISTINCT(x)?
You should use APPROX_DISTINCT(x) when your data has more than 1 million elements and you are looking to grasp the accurate characteristic of the dataset rather than to obtain precise numbers. That means APPROX_DISTINCT(x) is useful for all uses where precision is not an absolute requirement. For example, APPROX_DISTINCT(x) would be useful for KPI reportings where you need to calculate a Quarter-over-Quarter or Year-over-Year growth in the number of your gaming app’s unique users. In fact, Google’s BigQuery always uses HyperLogLog for distinct counting except when users deliberately specify that they want the exact counting.
When Should I NOT Use APPROX_DISTINCT(x)?
APPROX_DISTINCT(x) has few benefits when querying data with less than 1 million elements because the processing time is about the same as COUNT(DISTINCT x). Also, APPROX_DISTINCT(x) is accurate but still an approximation, so it cannot be used when you need precise counting of distinct values. Such cases include financial reporting where exact numbers are expected, or calculating daily unique user growth where the changes in numbers you expect are usually within the 1-2% range that can be confounded with HyperLogLog’s margin of error.
Cool, am I Now Smarter than My Competitors?
Yes because currently, over 60% of Treasure Data users use COUNT(DISTINCT x), but less than 10% of users use APPROX_DISTINCT(x). Give it a try and be amazed that queries that used to take hours get processed in minutes.
References