5 Use Cases Enabled by Docker 1.8’s Fluentd Logging Driver
5 Use Cases Enabled by Docker 1.8’s Fluentd Logging Driver
5 Use Cases Enabled by Docker 1.8’s Fluentd Logging Driver
Docker 1.8 Is Here with Fluentd
If you are interested in deploying Fluentd + Kubernetes/Docker at scale, check out our Fluentd Enterprise offering.
Docker 1.8 is coming soon! One of the major items in the 1.8 releases is its support for Fluentd as a Logging Driver. As the inventor of Fluentd, we are really excited about this progress. To quote Simon Hørup Eskildsen’s recent blog “Why Docker is Not Yet Succeeding Widely in Production”:
One example of an area that could’ve profited from change earlier is logging. Hardly a glamorous problem but nonetheless a universal one. There’s currently no great, generic solution. In the wild they’re all over the map: tail log files, log inside the container, log to the host through a mount, log to the host’s syslog, expose them via something like fluentd, log directly to the network from their applications or log to a file and have another process send the logs to Kafka. In 1.6, support for logging drivers was merged into core; however, drivers have to be accepted in core (which is hardly easy). In 1.7, experimental support for out-of-process plugins was merged, but – to my disappointment – it didn’t ship with a logging driver. I believe this is planned for 1.8, but couldn’t find that on official record. At that point, vendors will be able to write their own logging drivers. Sharing within the community will be trivial and no longer will larger applications have to resort to engineering a custom solution.
Therefore, we were stoked when Docker’s Fluentd Logging Driver landed. We were so excited that we immediately blogged how to set up Fluentd as a Docker Logging Driver.
In this blog post, we want to take a step back and summarize what use cases this new Fluentd + Docker integration enables. After all, Fluentd has 300+ plugins in its ecosystem =)
Use Case 1: Archiving Logs into Amazon S3
Using Fluentd’s S3 output plugin, the user can archive all container logs. By using tags intelligently, container names can map to buckets, allowing the logs to be organized at scale.
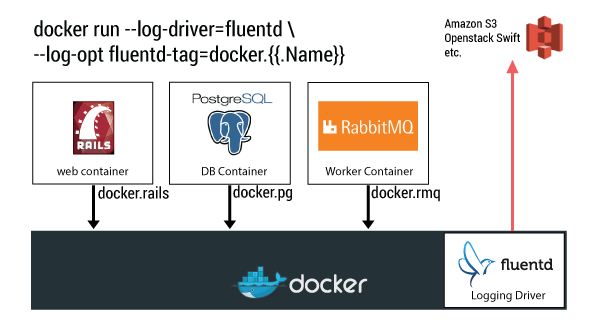
You never know when these logs are going to be useful, so start archiving them today.
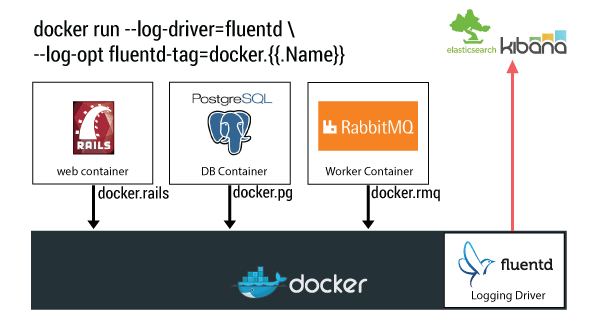
Use Case 2: Making Logs Searchable with Elasticsearch
Using FLuentd’s Elasticsearch output plugin, all your Docker logs become searchable. This is convenient for ops engineers who might need to search through dead containers’ logs.
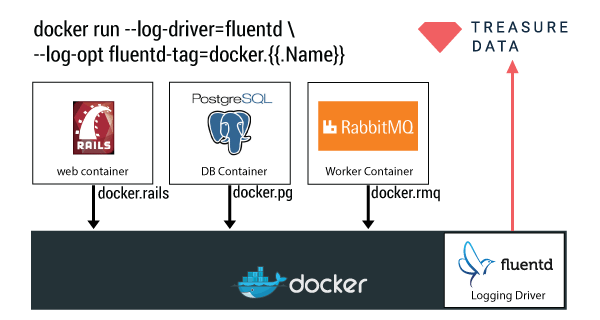
Use Case 3: Streaming Logs into Data Processing Backends
If you want to do analytics on your raw container logs, you can also send all Docker container logs to HDFS via the HDFS output plugin. Once the data is in HDFS, you can run any of the HDFS-friendly data processing engines (ex: Hive, Presto, Spark, Flink, Impala, etc. So many of these nowadays!) A shameless plug: if you don’t want to manage your analytics backend, you can always stream your Docker container logs to Treasure Data.
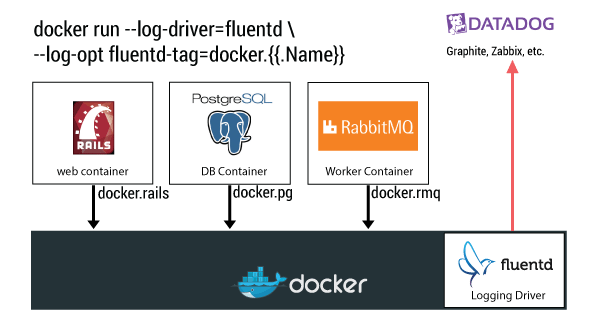
Use Case 4: Streaming Logs into Monitoring Services
If a whole bunch of Redis containers are having issues, you probably want to know ASAP. You can stream your container logs to monitoring services like Datadog and Librato. If you like to keep your stuff in-house, Fluentd supports these as well.
Use Case 5: Orchestration Frameworks
Among container orchestration frameworks, Kubernetes was early to adopt Fluentd as a log collector. At the time, the approach that they had to take was rather kludgy (certainly not their fault but Fluentd’s), but the new Fluentd Logging Driver, it’s easy for orchestration frameworks like Mesosphere and Docker Swarm to bundle Fluentd into the core.

By Satnam Singh “Collecting the Output of Containers in Kubernetes Pods”
We are super excited about Docker 1.8. Huge props to the Docker Core, and happy containerization!