Plug and Play Migration from Postgres to Redshift: One Billion Rows at a Time!
Plug and Play Migration from Postgres to Redshift: One Billion Rows at a Time!
Plug and Play Migration from Postgres to Redshift: One Billion Rows at a Time!
Migrating from Postgres to Redshift
Redshift is a popular cloud data warehousing service by Amazon. Redshift brings the power of Massively Parallel Processing (MPP) databases –powerful but expensive software once reserved for IT departments with deep pockets, often in the order of millions of dollars per year– to pretty much any company that can spend a couple of hundred of dollars per month.
Due to its “pay as you go” pricing model, Redshift is becoming quite dominant among fast-growing businesses like software startups. And, if there is anything that all startups share, it’s that they do not pay for their databases and tend to gravitate toward free alternatives like MySQL and Postgres; hence, many developers and DBAs are tasked with migrating data from existing MySQL or Postgres instances to Redshift. (Below, we will just consider Postgres, but most of these issues apply to MySQL as well).
In theory, this is simple. It goes like this:
- Dump all the data out of Postgres.
- Load the data.
- Profit!
But in reality, this is not as straightforward. For example:
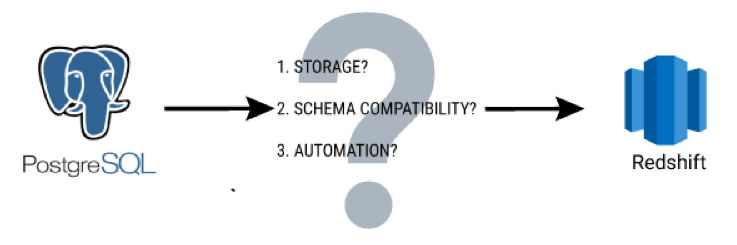
- Storage for the DB dump: Assuming you’re thinking of using Redshift, your data volume will be significant: probably tens of billions of rows if not more. Dumping all that data is non-trivial.
- Schema compatibility between Postgres and Redshift: Postgres and Redshift do not have the same type system, so you might run into issues while you are loading data into Redshift.
- Automation: Most likely, your migration won’t happen in one go. You will have to automate the process of loading new data into Redshift as you phase out Postgres. In fact, you might not actually be phasing out Postgres at all! You might simply be copying data from Postgres to Redshift so that you can offload analytics to Redshift while keeping Postgres as a transactional data store.
Anyhow, one thing is clear: the process of migrating from Postgres to Redshift can take a lot of time and effort.
But here is the good news: by Putting Treasure Data in the middle as a data lake (and an Redshift ingestion funnel) these issues are all addressed rather nicely.
- Dumping all the database dumps into Treasure Data: Treasure Data’s Data Connectors make it very easy to dump Postgres snapshots. Treasure Data adds roughly ~60 billion rows per day to its system, so your one-time DB dump of 20 billion rows is really not a big deal for us.
- Schema-on-read storage that’s compatible with Postgres and Redshift: Treasure Data is schema-on-read, meaning that you can dump any strongly typed database snapshots without worrying about compatibility. When you are loading data back to Redshift, you can cast data into appropriate types that Redshift understand.
- Automation through Scheduled Jobs: On Treasure Data, you have the ability to automate the process of loading data into Redshift, removing the need for yet another cron script or manually running COPY commands every day.
Postgres -> Treasure Data -> Redshift: HOWTO

Now, let’s see how all this is done. We are going to assume the following:
- We assume that you have a PostgreSQL database running on Amazon RDS. Also, we assume that your database has at least one port accessible from Treasure Data’s API servers. You can configure your security group to do this.
- We also assume that you have a Redshift instance running. Just like the Postgres instance, this Redshift instance must be accessible from Treasure Data.
- Finally, you need to install and configure Treasure Data toolbelt on your system.
Let’s get started.
-
- Create seed.yml.
config: in: type: postgresql host: postgresql_host_name port: 5432 user: your_postgres_username password: your_postgres_password database: your_postgres_database table: your_postgres_table select: "*" out: mode: append
- Create seed.yml.
-
- ‘Guess’ the data.
$ td connector:guess seed.yml -o td-bulkload.yml
- ‘Guess’ the data.
-
- Preview the data before loading it into Treasure Data. (Click the image to enlarge.)
$ td connector:preview td-bulkload.yml

- Preview the data before loading it into Treasure Data. (Click the image to enlarge.)

-
- Create the database on Treasure Data.
$ td db:create your_treasure_data_database
- Create the database on Treasure Data.
-
- Create the tables on Treasure Data.
$ td table:create your_treasure_data_database your_treasure_data_table
- Create the tables on Treasure Data.
-
- Load the data into your Treasure Data table:
$ td connector:issue td-bulkload.yml –database your_treasure_data_database –table your_treasure_data_table –time-column your_timestamp_column
- Load the data into your Treasure Data table:
-
- Go to console.treasuredata.com and query your table. Let’s get first 10 items sorted by a value.
SELECT * FROM your_treasure_data_table ORDER BY your_value ASC LIMIT 10
- Go to console.treasuredata.com and query your table. Let’s get first 10 items sorted by a value.
-
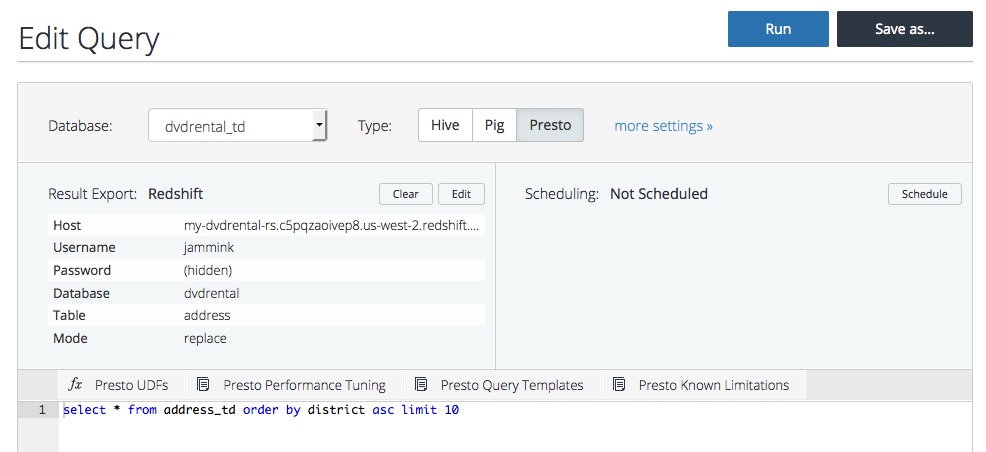
- Set it up to export the query results to Redshift.
Host: my-amazon_host-rs.c5pqzaoivep8.us-west-2.redshift.amazonaws.com #Example
Username: your_amazon_redshift_username
Password: your_amazon_redshift_password
Database: your_amazon_redshift_database
Table: your_amazon_redshift_table
Mode: append
Method: insert
- Set it up to export the query results to Redshift.
-
- Run the query.
-
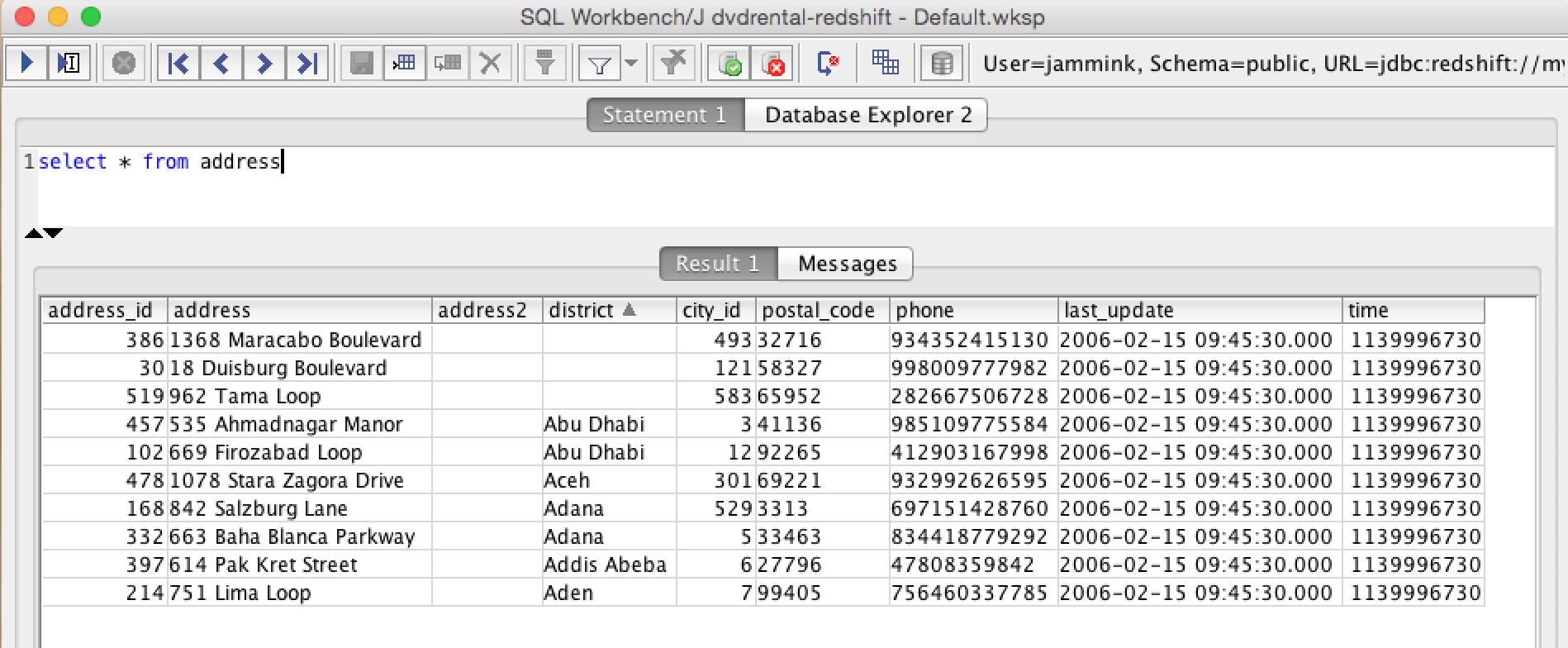
- View and query the results on Redshift. You can connect to your Redshift instance with SQL Workbench (or similar) and query your Redshift data.
- View and query the results on Redshift. You can connect to your Redshift instance with SQL Workbench (or similar) and query your Redshift data.
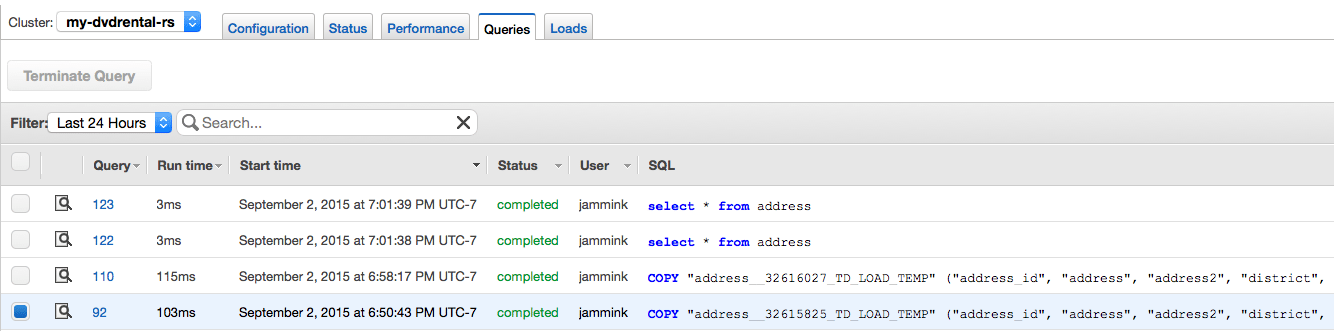
- Finally, you can check your transaction log on Redshift. You can get a sense of the costs savings by doing this, as you will need to do fewer queries and transformations directly on Redshift.
What’s next?
As you have seen, Treasure Data provides a great solution to simplify the migration from Postgres to Redshift. What’s more, it can be use to build a cloud data lake that can unify your analytics infrastructure and publish results into various target systems, including Redshift.
If this sounds like something that piques your interest, click here to request a demo and see what Treasure Data can do for your business.