Enhance your Google BigQuery with Treasure Data Result Output
Enhance your Google BigQuery with Treasure Data Result Output
Enhance your Google BigQuery with Treasure Data Result Output
Stay tuned for our video of this integration!
![]()
Google BigQuery is the choice for many. It’s the go-to for interactive analysis of enormous datasets and can process billions of rows in seconds. With no infrastructure to manage and the need for an administrator eliminated (in many cases), you can use SQL, pay as you go, and get up and running on your analytics fairly quickly. It’s also affordable, super fast (see above), very secure, and, with a range of integrations and partners, quite well positioned to be an analytics choice for many applications.
We’d like to propose a way to make Google BigQuery even better, so without further ado, let’s have a look.
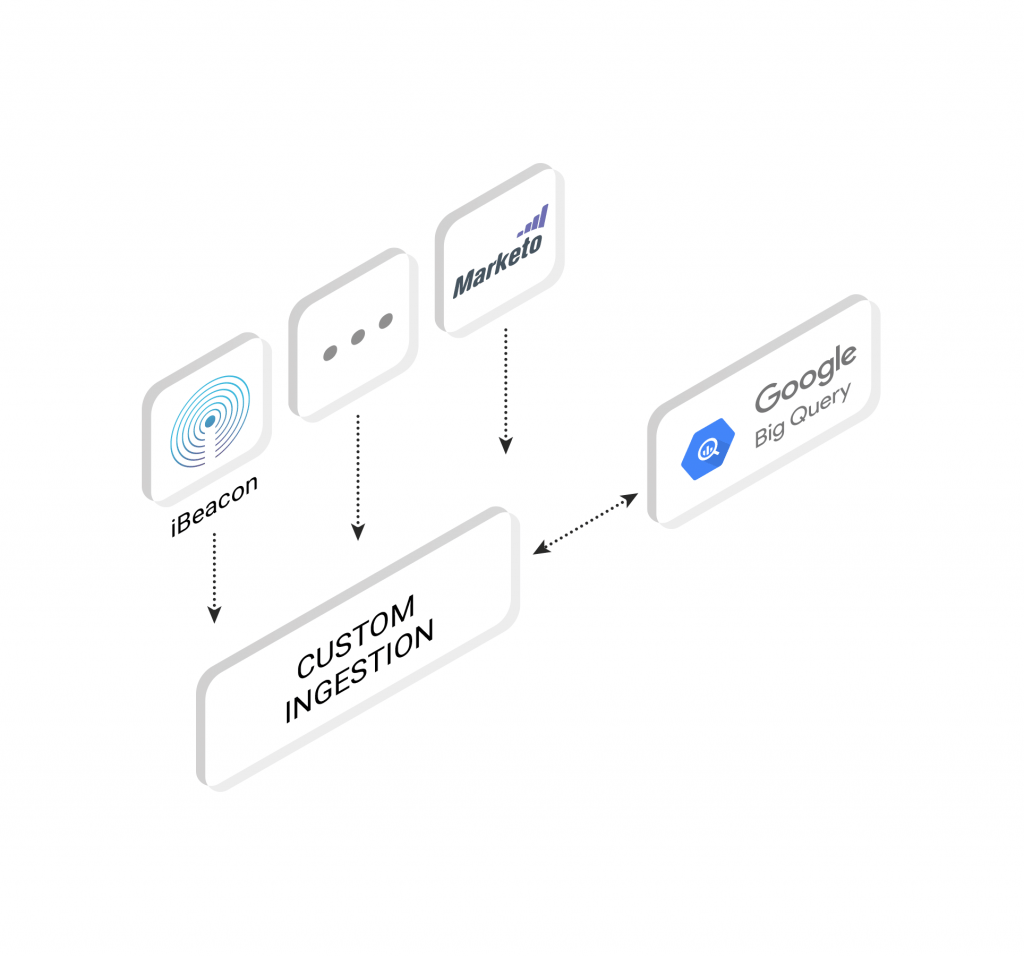
Schema
Google BigQuery has an intuitive, easy interface for creating new tables and managing schemas. With a couple of simple clicks, you can set up or adjust your table schema, and you’re ready for ingestion.
Well…certainly as long as the data you’re ingesting originates from the same source (typically Google Cloud Storage or Google Cloud Datastore), and sticks to the schema you’ve specified. Unfortunately, if it does not, the ingestion may hit some roadblocks.
Treasure Data is schema-on-read, so you can ingest your data from a variety of sources and formats, query that data into the format you’ve set up for Google BigQuery, and then import to BigQuery with ease!
Engineering Overhead
You may need to do a fair bit of tweaking and reformatting of your apps and data to get it to conform to your schema or schemas in BigQuery, so you’ll need resources both to instrument your applications as well as to optimize the ingestion pipeline.
Treasure Data can save you a bit of time with our new Connector UI. Now, it’s as simple as clicking the connector for the data source you want in the browser and doing some simple authentication and configuration. Done!
Native Scheduling
With Treasure Data, you can schedule both queries themselves, as well as result output to BigQuery. Also, Treasure Data can be used to avoid the problem with billing tier thresholds in BigQuery: that is, if you’ve set your BigQuery billing tier threshold too low, your batch queries may simply stop running within the instance. As Treasure Data works on more of a fixed cost model (as opposed to BigQuery’s variable one), you can bypass some of these issues.
Now, let’s have a look at how this all works together.
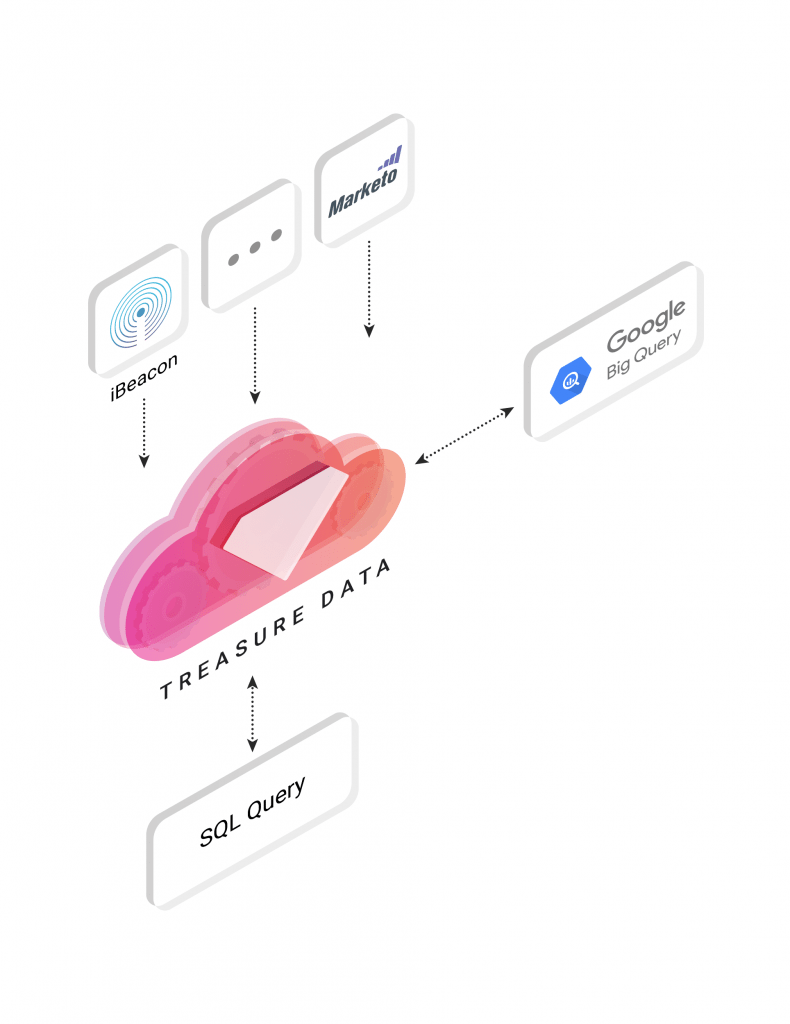
Setting it all up
Let’s summarize the steps you’ll need to get going.
Get your BigQuery credentials
First, you’ll need to get your BigQuery Project ID and JSON Credential.
Integration between Treasure Data and Google BigQuery are based on server-to-server API authentication. You can get your Project ID from your Google Developer Console by visiting your project -> Switch to Project -> Manage Project as shown here.
JSON Credential is a small bit of JSON which we will use for authentication between Treasure Data and BigQuery. To get this, visit Credentials -> API & Auth, selecting Service Account. After selecting JSON in the next pane, and clicking Create, you’ll have your JSON credentials. Copy these over to a text file for later.
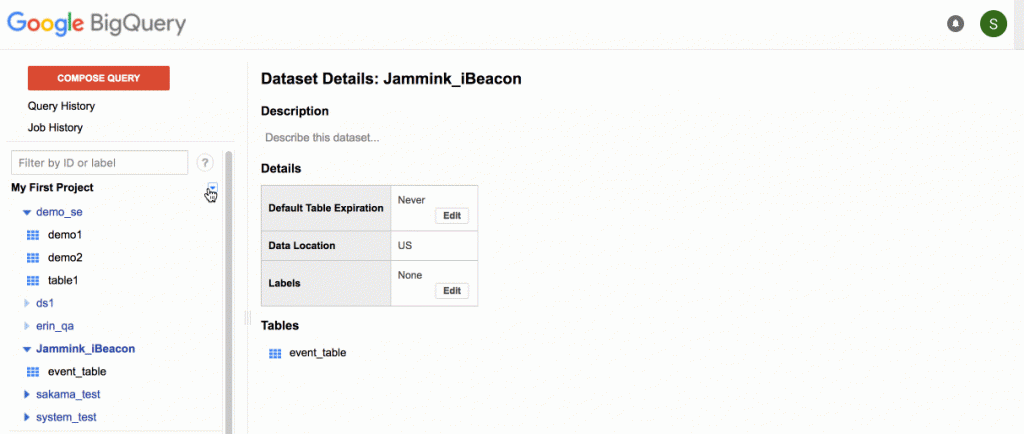
Create your Dataset and Table on BigQuery Console
Create your Dataset and Table on BigQuery Console. Note the schema, order of fields and data type of each field. Order is important when structuring queries to export results from Treasure Data to Big Query, so make a note of the order of the fields in the schema.
Query your data on Treasure Data and export results to BigQuery
Go to Treasure Data Console -> query editor, check output results, and fill the result export dialog with the credentials and schema information from your BigQuery instance. Remember to paste in your JSON Credential from the earlier step.
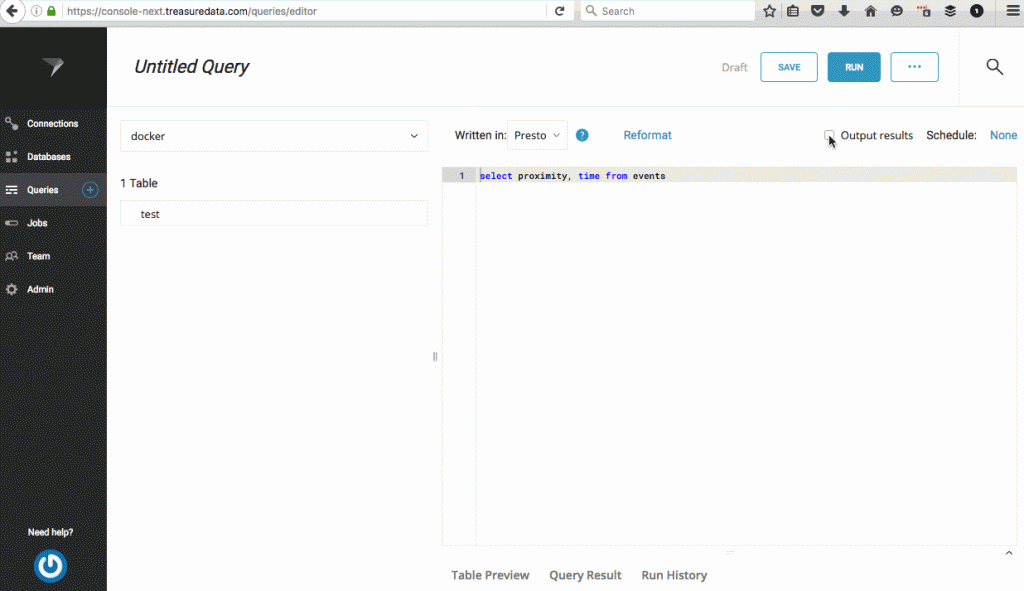
Once you’ve set this up, write the query. As mentioned previously, your query result must match the order of your pre-defined schema on BigQuery.
Finally, clicking the ![]() button exports your query results to BigQuery.
button exports your query results to BigQuery.
What’s next?
Want to get the best out of your data analytics infrastructure with the minimum of expense, hassle, and configuration? Then try out Treasure Data.
Our universal data connector can route almost any data source to almost any data destination. Want to see an integration we don’t support yet? Ask us!
Sign up for our 14-day trial today or request a demo! You can also reach out to us at sales@treasuredata.com!