UDP: A New Partitioning Strategy Accelerating CDP Analytic Workloads
UDP: A New Partitioning Strategy Accelerating CDP Analytic Workloads
UDP: A New Partitioning Strategy Accelerating CDP Analytic Workloads
In Treasure Data, the customer’s data is stored in our proprietary storage system called PlazmaDB. This storage system is composed of PostgreSQL and Amazon S3. PostgreSQL is used to hold the metadata of the partitions in Amazon S3 such as S3 path, database name, and index.
The partitions in Treasure Data are split based on the time the records were generated, with the smallest time and largest time in a partition recorded as metadata in PostgreSQL. The metadata information is used by query engines like Presto to identify which partitions fall within a specified time range. Combined with the database name, this metadata forms a multi-column index that makes searching the target partitions efficient since the user can enable the engine to skip having to read unneeded data by specifying the database name and the time range to query. This is the mechanism working behind the queries run within Treasure Data.
SELECT
symbol, volume, close
FROM
nasdaq
WHERE
TD_TIME_RANGE(time, '2018-01-01', '2018-02-01')
Presto running in Treasure Data is able to push down the time range predicate (TD_TIME_RANGE) by retrieving the information about the target partitions from Plazma. The engine will only download the partitions not filtered out in advance by Plazma. We call this mechanism time index pushdown. This optimization is based on the original observation that OLAP queries our customers submit focus the analysis in specific time range(s) (e.g. earnings in the last month, page views of this week, daily active users).
But another pattern of workload recently emerged is that originating from customer data platform (CDP) analytics. CDP is basically designed to create segments of audiences. For example, we may want to identify customers whose age is over 30 among those who visited our eCommerce site. In that case, we should be able to efficiently filter out customer records whose ages are less than 30, while time index pushdown optimization is only enabled when we specify the target time range because Plazma only has indexes on database name and time. This motivated the development of UDP.
UDP: User Defined Partitions
User Defined Partition, UDP is a new feature to create more dimensions which enable us to filter out more partitions flexibly. It provides a way to create an index on any column in Plazma. The idea is simple. Partitions are further split by the specified columns and stored separately in logical segmentations called buckets. A bucket holds only records which have the same value in terms of the specified column. For example, let’s create buckets corresponding to the previous example, ‘customers whose age is over 30 among those who visited our eCommerce site’:
| Name | Age | Hobby |
|---|---|---|
| Nobita | 32 | Crying |
| Suneo | 31 | Travel |
| Takeshi | 18 | Fighting |
In order to efficiently search customers whose age is 30, it is necessary to create buckets based on the age column’s values so that we can skip reading the record corresponding to ‘Takeshi’ because Plazma only returns partitions corresponding to the ‘over 30’ bucket. As you may know, the basic concept of bucketing is similar to that of time index pushdown:
- Extract the filtering condition from the predicate of a query
- Convert the condition value into a bucket key using a hash function
- Pushdown the bucket key to Plazma and exclude the information of unnecessary partitions
- Create a distributed plan to execute a query only with the targeted partitions
What we want to note here is that we can use UDP without losing the benefit of time index pushdown. This diagram shows how partitions are divided: the gray box specifies a partition file and the pink one is a partition to be read by a query. The right chart shows how many partitions we can skip reading using UDP: UDP enables us to read only 2 partitions while it’s necessary to read 3 partitions in the default case.
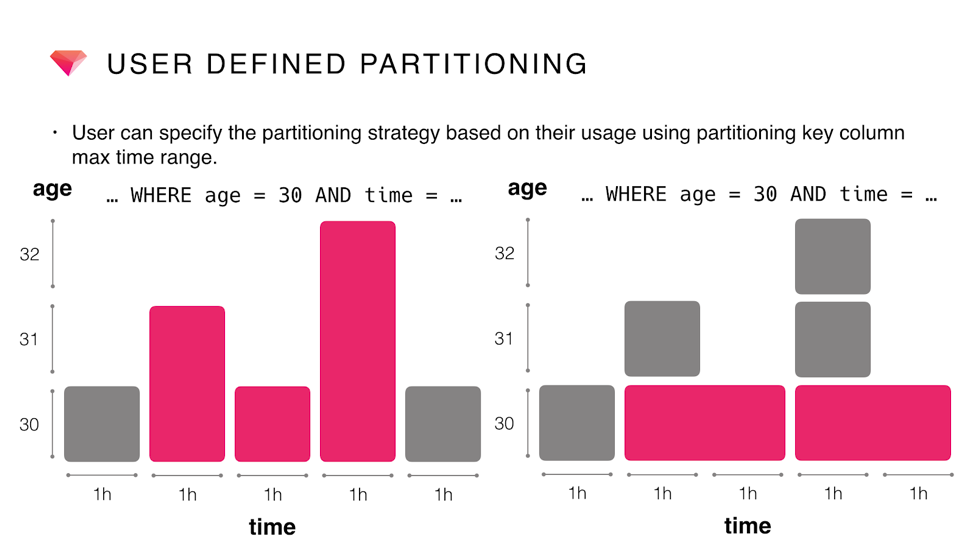
Introducing UDP results in partitions having finer granularity because they are split by multiple dimensions. If you specify a value for one of the buckets and time range, Plazma still returns partitions filtered out according to both these conditions. For example:
SELECT
name, age
FROM
customers
WHERE
age = 30
AND TD_TIME_RANGE(time, '2018-04-01', '2018-05-01')
This query is optimized by UDP and time index pushdown. In other words, Presto downloads only partition files which include records whose age is 30 and generated in April. If you have a lot of partitions in the table, this optimization can save a fair amount of processing time by reducing the bandwidth required to download the partition files.
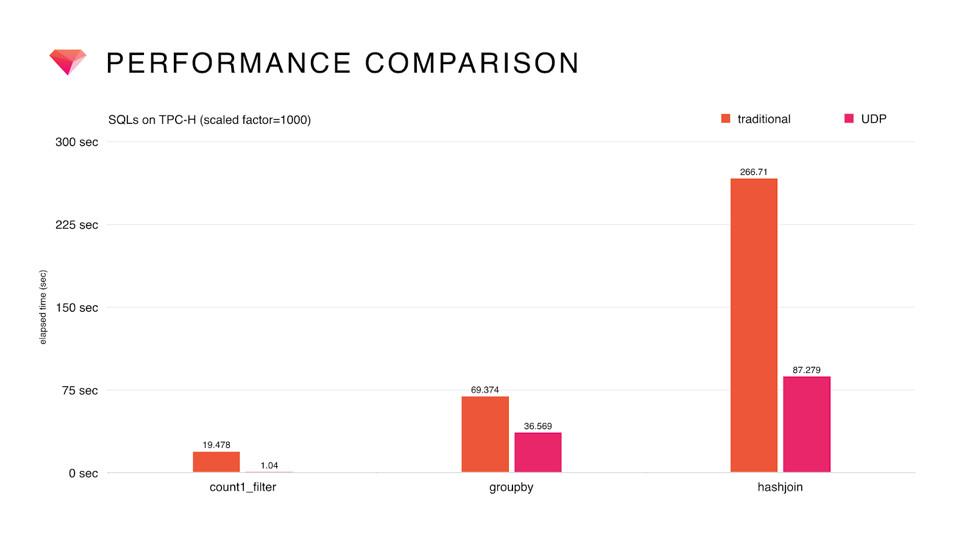
Here is a chart showing how much performance improvement can be achieved by UDP. Simple filtering in the left-most use case (count1_filter) becomes much faster. But why are aggregations (groupby) and joins (hashjoin) also faster without specifying a filtering predicate? It must be because the engine keeps reading the same partitions in such cases: that is how colocated join optimization works.
Colocated Join
Not only is query time and bandwidth usage more efficient with the UDP partitioning strategy, there’s an additional advantage by using UDP. Presto downloads partition files in a distributed manner using multiple processing nodes if the query has an aggregation operator or a join operator, Presto can make use of colocated join optimization by leveraging the knowledge of which bucket needs to be read when it creates a distributed query plan. The result is being able to optimize the aggregation or join performance by collecting records with the same bucket key in the same processing nodes during the processing of downstream operators such as table scans, which avoids unnecessary data shuffling between nodes during the processing of the upstream operators.
The following chart illustrates how colocated join works. The records in a left table and right table must be re-distributed by join key in case of a distributed join. Redistribution by shuffle operation is costly, particularly in terms of network bandwidth. Colocated join optimization enables Presto to collect records with same join key in the same machine in advance (e.g. during a table scan), thus reducing or omitting shuffling later:
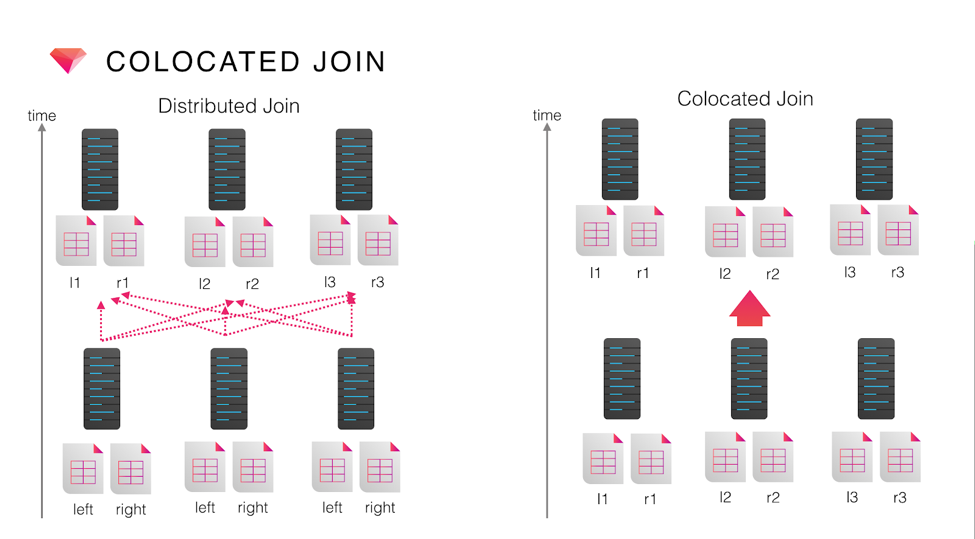
The UDP feature provides bucket key information to the Presto query planner so that Presto can collect partitions which belong to the same bucket. Thanks to this optimization, a query can be faster even if it does not filter out partitions aggressively in advance: as a consequence the performance of a query which required high-cost shuffle operations could possibly be largely improved.
Limitations
While promising, the Treasure Data UDP optimization is currently only effective for filtering involving = comparisons and ‘IN’ operators. This is because Presto calculates the bucket keys from the SQL predicate expression internally; in practical terms, the filtering comparison ‘WHERE age = 30’ will create a plan to get partitions whose key is exactly hash(30).
For example, UDP optimization is enabled in the following cases:
SELECT
name, age
FROM
customers
WHERE
age = 30
or
SELECT
name, age
FROM
customers
WHERE
age IN (10, 20, 30)
But it won’t work as expected in the following case:
SELECT
name, age
FROM
customers
WHERE
age < 30
Presto is unable to determine all bucket keys needed in this case because it does not know the granularity of the age column and the lower bound of the possible values the column can contain: this is because the UDP metadata does not provide Presto with this information.
Here is another limitation. The maximum number of buckets is fixed one. You cannot change that after you create UDP table in Treasure Data. A large number of buckets splits the space with more fine granularity so that you can filter out unnecessary data in fine-grained manner. But at the same time, partition files tend to be smaller which cause the overhead of reading time. Overall you may need to pay a little attention to decide how many buckets are needed in your use case.
Recap
UDP was mainly developed for accelerating the workloads introduced by the Treasure Data CDP. At the same time, the mechanism is leverageable to bring performance improvements to all Treasure Data queries having a filter predicate on bucket key column(s).
If you have a query you believe could leverage this optimization, please contact our support team and we will be happy to provide assistance.
This topic was originally introduced in our technology meetup, Plazma. For more details, please see the slides at this link https://www.slideshare.net/lewuathe/user-defined-partitioning-on-plazmadb.