Understanding the Book-Crossing Dataset: Setup
Understanding the Book-Crossing Dataset: Setup
Understanding the Book-Crossing Dataset: Setup
I'm a data scientist at Treasure Data. In a series of blog entries, I want to introduce how to use our platform by interacting with a concrete dataset. I chose the publicly available Book-Crossing Dataset as our base data.
What’s in the Dataset?
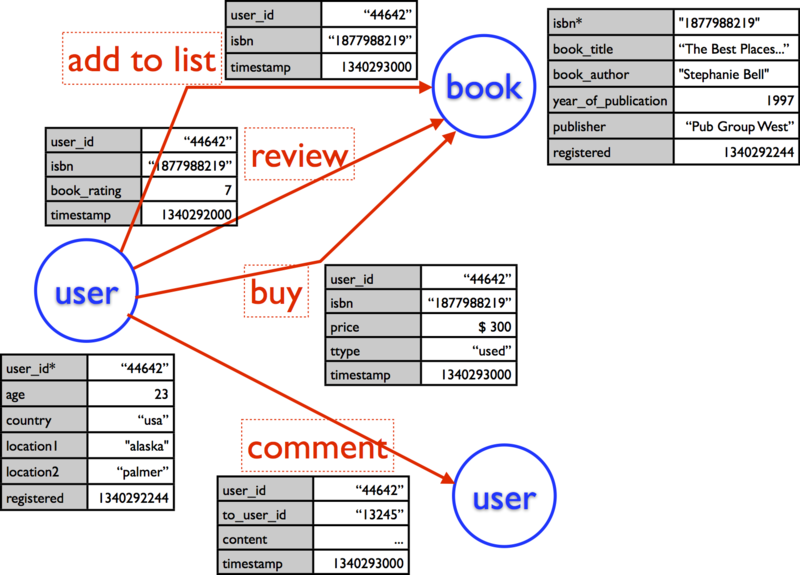
The Book-Crossing Dataset consists of three logs: users, books and ratings. Let’s see what kind of data is inside.
# users "UserID";"Location";"Age" "1";"nyc, new york, usa";NULL "2";"stockton, california, usa";"18" # books "ISBN";"BookTitle";"BookAuthor";"YearOfPublication";"Publisher";"ImageURLSizeS";"ImageURLSizeM";"ImageURLSizeL" "0195153448";"Classical Mythology";"Mark P. O. Morford";"2002";"Oxford University Press";"<a href="http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg"> http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg</a>";"<a href="http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg"> http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg</a>";"<a href="http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg"> http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg</a>" "0002005018";"Clara Callan";"Richard Bruce Wright";"2001";"HarperFlamingo Canada";"<a href="http://images.amazon.com/images/P/0002005018.01.THUMBZZZ.jpg"> http://images.amazon.com/images/P/0002005018.01.THUMBZZZ.jpg</a>";"<a href="http://images.amazon.com/images/P/0002005018.01.MZZZZZZZ.jpg"> http://images.amazon.com/images/P/0002005018.01.MZZZZZZZ.jpg</a>";"<a href="http://images.amazon.com/images/P/0002005018.01.LZZZZZZZ.jpg"> http://images.amazon.com/images/P/0002005018.01.LZZZZZZZ.jpg</a>" # ratings "UserID";"ISBN";"BookRating" "276725";"034545104X";"0" "276726";"0155061224";"5"
When I study new logs (By the way, I love interacting with logs and data in general), the first question I ask is, are they "status" or "action"?
“Status” logs describe a state of an entity. In the current case, users and books are status logs. For example, users describe the age and location of each user while books record the title, author, year of publication and publisher of each book.
“Action” logs describe an action between (or among) entities. In the current case, ratings is an action log because in each line, a user (entity 1) give a rating (action) to a book (entity 2).
Setup!
Before we start analyzing the data, we should put it on Treasure Data Platform.
- First, you should sign up and get an account.
- You also need to download the command line client on the <a href=”http://toolbelt.treasure-data.com” target=”_blank”>tool belt page.
-
Finally, you need to download the dataset. I've put together a MessagePack formatted dataset for you.
Now that you have everything, let's create tables to which we can upload the data.
$ td db:create book_crossing_dataset # create a table $ td table:create book_crossing_dataset users $ td table:create book_crossing_dataset books $ td table:create book_crossing_dataset ratings # import data $ td table:import book_crossing_dataset users --format msgpack -t time BX-Users.msgpack.gz $ td table:import book_crossing_dataset books --format msgpack -t time BX-Books.msgpack.gz $ td table:import book_crossing_dataset ratings --format msgpack -t time BX-Ratings.msgpack.gz # Let's check $ td tables +------------------------------+---------------------------------+------+-----------+ | Database | Table | Type | Count | +------------------------------+---------------------------------+------+-----------+ | book_crossing_dataset | books | log | 271376 | | book_crossing_dataset | ratings | log | 1149780 | | book_crossing_dataset | users | log | 278858 | +------------------------------+---------------------------------+------+-----------+
td help is your friend
You might say, “Wow, what are those commands?” Don’t fret, you can list all the commands with td help:all and td help shows all the options for the particular command. For example, here is all the options for td query, the command we will be using to query our uploaded data.
$td help query usage: $ td query example: $ td query -d example_db -w -r rset1 "select count(*) from table1" description: Issue a query options: -d, --database DB_NAME use the database (required) -w, --wait wait for finishing the job -o, --output PATH write result to the file -f, --format FORMAT format of the result to write to the file (tsv, csv, json or msgpack) -r, --result RESULT_URL write result to the URL (see also result:create subcommand) -u, --user NAME set user name for the result URL -p, --password ask password for the result URL
Writing some basic queries
Now, let's look at some data. One handy command to take a peek at data is td table:tail. Here is an example.
$ td table:tail book_crossing_dataset users -n 1 -P
{
"user_id":"44642",
"age":"23",
"country":"usa",
"location1":"alaska",
"location2":"palmer",
"time":1340292244,
}
But that's just tailing your table. The command you want to use is the aforementioned td query. Here are a couple of examples.
$td query -w -d book_crossing_dataset "SELECT * FROM users LIMIT 5" ... Result : +---------+------+----------------+----------------+---------------+------------+ | user_id | age | country | location1 | location2 | time | +---------+------+----------------+----------------+---------------+------------+ | 44632 | NULL | spain | n/a | arrecife | 1340292244 | | 44633 | NULL | usa | north carolina | durham | 1340292244 | | 44634 | 37 | united kingdom | england | ryde | 1340292244 | | 44635 | 36 | usa | new york | mount vernon | 1340292244 | | 44636 | 24 | japan | n/a | tokyo | 1340292244 | +---------+------+----------------+----------------+---------------+------------+
That just looked up five users. Now, let's count how many users there are.
$td query -w -d book_crossing_dataset "SELECT COUNT(*) AS cnt FROM users"
...
Result :
+--------+
| cnt |
+--------+
| 278858 |
+--------+
Wrap-up
That's it for today. In the next entry, we will analyze data using td query (with a bunch of pretty graphs!) Stay tuned!