Move Fast, Add Value: Why Hadoop-Veteran Viki Uses Treasure Data
Move Fast, Add Value: Why Hadoop-Veteran Viki Uses Treasure Data
Move Fast, Add Value: Why Hadoop-Veteran Viki Uses Treasure Data
Over the past year, we’ve done a lot to be proud of. We built a high performance, Hadoop-based data analytics platform from scratch. For next-generation ETL and real-time data collection, we authored td-agent and open-sourced it as Fluentd, which now has ~800 stars on GitHub.
But our biggest achievement? Our happy customers. Today, we want to introduce one of them, Viki.com.
Viki.com: A global video platform
 Viki is a global online video service that lets millions of people watch their favorite TV shows, movies, sports games, and more. What really sets it apart is its international viewership: Viki’s content is available in over 150 languages, all translated by its user community.
Viki is a global online video service that lets millions of people watch their favorite TV shows, movies, sports games, and more. What really sets it apart is its international viewership: Viki’s content is available in over 150 languages, all translated by its user community.
No Stranger to Hadoop
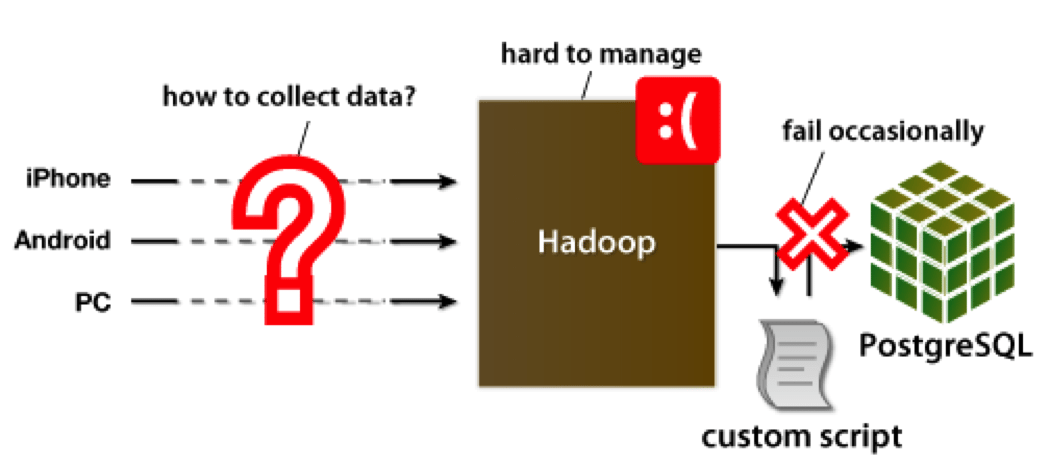
Viki.com is no stranger to Hadoop. They have very talented engineers, and before introducing Treasure Data, they used to run their own Hadoop cluster to analyze millions of pageview and user event data.
But several months in, Viki had an epiphany: Hadoop’s biggest cost is not initial setup but ongoing management and tuning. They noticed that they were spending more and more time just to ensure their cluster held up in the face of surging traffic.
BEFORE TREASURE DATA
Treasure Data: Move Fast, Add Value
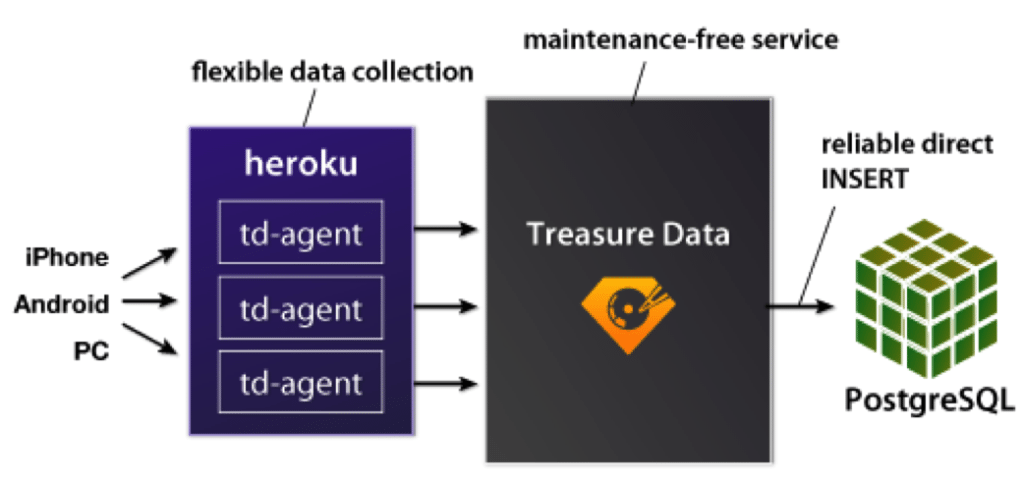
Thus, when Viki engineers stumbled on Treasure Data, they immediately saw its value proposition: taking operation cost out of Hadoop and Big Data analytics, freeing up engineers’ time, and accelerating the core product’s development.
This is great for business, too. Good engineers are hard to find and even harder to hire. If you run your own Hadoop cluster, you need to dedicate some of your best engineers to its maintenance. Sure, Hadoop itself is free, but when you consider associated engineering cost, it quickly becomes very expensive.
AFTER TREASURE DATA
Support, Support, Support!
The other day, Huy, Viki’s software engineer who contributed a “success story” write-up earlier, had questions about the data transport between Treasure Data and Viki’s PostgreSQL (see the above diagram). Our engineers dug into his questions immediately, made a couple of technical suggestions, and within one week, Huy sped up the data transport by several fold.
In the end, there is only one question that matters: are we adding value for our customers? We still have a long journey ahead of us, but the encouraging feedback from our customers leads us to think we are on the right track =)