Managing the Data Pipeline with Git + Luigi
Managing the Data Pipeline with Git + Luigi
Managing the Data Pipeline with Git + Luigi
One of the common pains of managing data, especially for larger companies, is that a lot of data gets dirty (which you may or may not even notice!) and becomes scattered around everywhere. Many ad hoc scripts are running in different places, these scripts silently generate dirty data. Further, if and when a script results in failures — often during the night, as luck would have it — it is very difficult to determine how to recover from the failure unless the maintainer of the script is available. The more the company grows, more messy data is generated and scattered, and the data pipeline becomes harder to maintain.

Existing Approaches
To attack these problems, people today rely on ETL tools to centralize ETL job definitions and define and manage job dependencies. These tools solve a lot of problems: For example, people can construct jobs and their dependencies visually. In this way, people stop writing one-time ad hoc scripts.
Although this approach solves a couple of key challenges, we still hear a few key problems.
- It’s hard to backtrack to determine why and how the specific data set was created
- It’s hard to track the changes of the data pipeline
- ETL tools are designed for row-by-row processing, not fit for big data
- ETL processes aggregate data but have no access to raw data
Managing a Robust Data Pipeline with Git+Luigi
The team at Treasure Data has talked with a lot of data engineers and data scientists, and we discovered one common approach: managing the entire data pipeline with Git and Luigi.
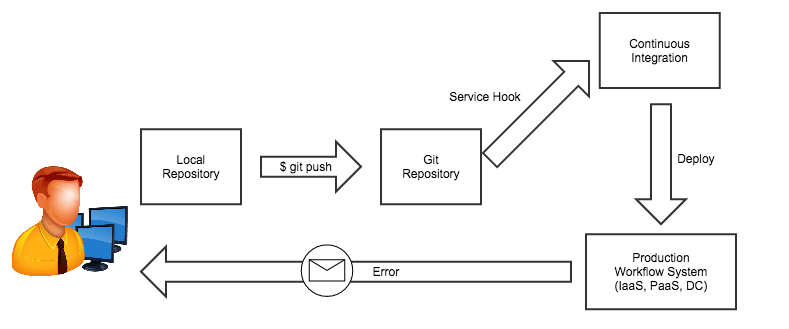
Why Git?
Git is an open source distributed version control system that can be used to keep track of all the changes to the data pipeline and leverage existing developer tools. The approach is to prepare a single Git repository, which contains all the scripts, schedules, and their dependencies. When the code gets changed, the changes are immediately delivered to the production system. Developers can collaborate, review, and complete the jobs with familiar tools like GitHub, JIRA, etc.
Why Luigi?
Luigi is an open source Python-based data framework for building data pipelines. Instead of using an XML/YAML configuration of some sort, all the jobs and their dependencies are written as Python programs. Because it’s Python, developers can backtrack to figure out exactly how data is processed.
The framework makes it easier to build large data pipelines, with built-in checkpointing, failure recovery, parallel execution, command line integration, etc. Since it’s a Python program, any Python library assets can be reused. The Luigi framework itself is a couple of thousand lines, so it’s also easy to understand the entire mechanism.
Facebook built a similar internal system called Dataswarm (Video), which allows developers to manage the entire data pipeline on Git + Python.
While Luigi was originally invented for Spotify’s internal needs, companies such as Foursquare, Stripe, and Asana are using it in production.
Why Git + Luigi?
In short, Git + Luigi makes it easy to manage, write, collaborate, and maintain data pipelines for large teams.
How to Manage the Data Pipeline with Luigi + Treasure Data
In this section, we’ll show you how to manage the data pipeline with Git+Luigi, which processes data on Treasure Data.
The luigi-td-example repository contains a couple of sample workflows. This repository depends on the library called Luigi-TD, which makes it easier to write and define dependencies of Treasure Data jobs. Here’s an example workflow written in Luigi: Execute large aggregation with Hive (sample_datasets.www_access -> test_db.test_table), issue Presto query (test_db.test_table) to the aggregated table, and download the result as CSV (./tmp/Task3.csv).
import luigi
import luigi_td
# Issue Hive query and insert result into test_db.test_table on TD
class Task1(luigi_td.Query):
type = 'hive'
database = 'sample_datasets'
def query(self):
return "SELECT path, COUNT(1) cnt FROM www_access GROUP BY path ORDER BY cnt"
def output(self):
return luigi_td.ResultTarget('tmp/Task1', 'td://@/test_db/test_table?mode=replace')
# Issue Presto query against test_db.test_table
class Task2(luigi_td.Query):
type = 'presto'
database = 'test_db'
def requires(self):
return Task1()
def query(self):
return "SELECT COUNT(1) FROM test_db.test_table"
def output(self):
return luigi_td.ResultTarget('tmp/Task2')
# Download the result, and format as CSV
class Task3(luigi.Task):
def requires(self):
return Task2()
def output(self):
return luigi.LocalTarget('tmp/Task3.csv')
def run(self):
target = self.input()
with self.output().open('w') as f:
target.result.to_csv(f)
if __name__ == '__main__':
luigi.run()
Each task defines its dependency within the requires() function, and its result set in the output() function. These are automatically recognized by the framework and executed based on their dependencies. Here’s an example output of executing the above tasks locally with Luigi.
$ python tasks.py Task3 --local-schedulerINFO: Done scheduling tasks INFO: Running Worker with 1 processes INFO: [pid 57078] Worker Worker(salt=329919253, workers=1, host=k.local, username=kzk, pid=57078) running Task1() INFO: [pid 57078] Worker Worker(salt=329919253, workers=1, host=k.local, username=kzk, pid=57078) done Task1() INFO: [pid 57078] Worker Worker(salt=329919253, workers=1, host=k.local, username=kzk, pid=57078) running Task2() INFO: [pid 57078] Worker Worker(salt=329919253, workers=1, host=k.local, username=kzk, pid=57078) done Task2() INFO: [pid 57078] Worker Worker(salt=329919253, workers=1, host=k.local, username=kzk, pid=57078) running Task3() INFO: [pid 57078] Worker Worker(salt=329919253, workers=1, host=k.local, username=kzk, pid=57078) done Task3() INFO: Done
This repository can easily be deployed on Heroku with just one click. You can start building your data pipeline immediately.
We use Git + Luigi + Treasure Data to automate our internal reporting. We have a centralized Git repository called td-workflow, which contains the data workflow for the entire company. This pipeline aggregates the data on Treasure Data, issues multiple jobs, and pushes the aggregated results into our internal Tableau Online dashboard or other tools such as Preact.
Conclusion
Working with data at scale is definitely a challenge for a lot of companies, but we’ve seen the trend of using Git + Luigi for managing the data pipeline. This combination makes it easier to build, maintain, and collaborate with other members in the company to extract values from an ocean of data.
- Luigi documentation
- Luigi-TD documentation
- td-luigi-example Git repository
Contact us for more information about how to use Git + Luigi and Treasure Data.
Acknowledgements
Keisuke Nishida developed Luigi-TD, and Yuu Yamashita developed td-client-python, Treasure Data’s REST API wrapper for Python. For information about Luigi developers, visit here.