Eliminating Schema Rot in MPP Databases Like Redshift
Eliminating Schema Rot in MPP Databases Like Redshift
Eliminating Schema Rot in MPP Databases Like Redshift
The MPP database is an incredible piece of technology. These databases run large-scale analytic queries very quickly, making them great tools for iterative data exploration. With a cloud offering like Redshift in the market, MPP databases are enjoying increasing adoption today outside of enterprise IT.
However, like any other great technology, they excel in some areas more than others. Today, schema management and data loading are two areas where MPP databases like Redshift require a lot of technical skills and engineering effort. But here is great news: This problem is solved by using Treasure Data alongside MPP databases.
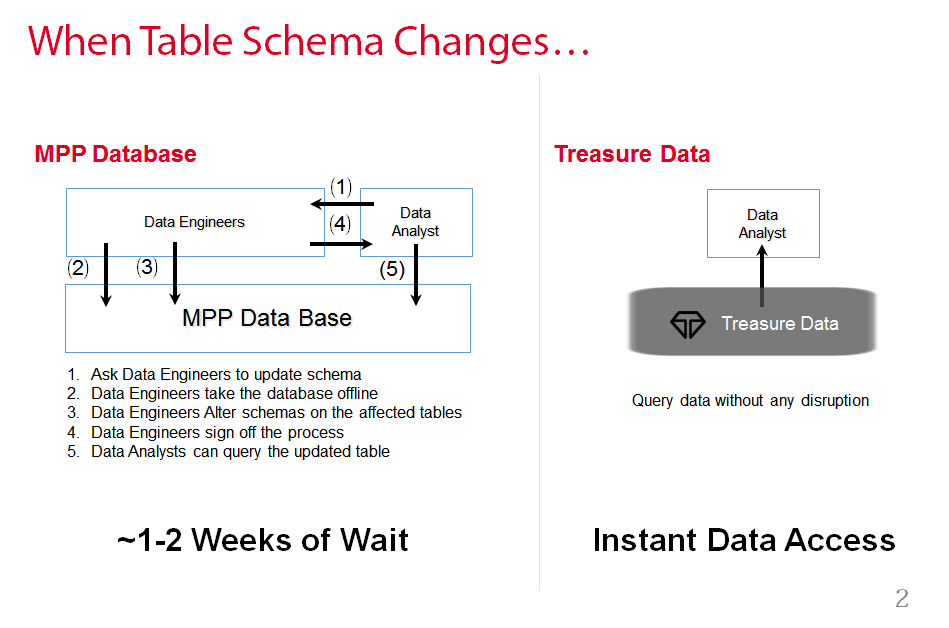
MPP databases have a lot of use cases, ranging from data warehousing to log data analysis. Here, I will show how to eliminate schema management and data loading challenges using the example of log data analysis. In the rest of the article, we will focus on Redshift, a cloud-based MPP database that integrates very well with Treasure Data.
Schema Management Hell
For log-type data, the most common way of loading data into Redshift is via Amazon Simple Storage Service (S3). Using S3 as the landing area, log data is copied periodically to Redshift for SQL-powered analysis.
But here is the challenge. Unlike structured RDBMS data, the format of log data evolves. The launch of a new service, tweaks to an existing mobile app, etc. all cause data formats to change, requiring schema updates downstream.
And during a schema update, a Redshift cluster needs to be set read-only, which can take hours for large tables. During the schema update, the user cannot query the new data from Redshift.
A common solution to this problem is to set up Hive and run that against S3. However, this is not a complete solution because for many queries, Redshift and Hive have different latency profiles. Plus, why should you need to set up another query system just to cope with Redshift schema changes?
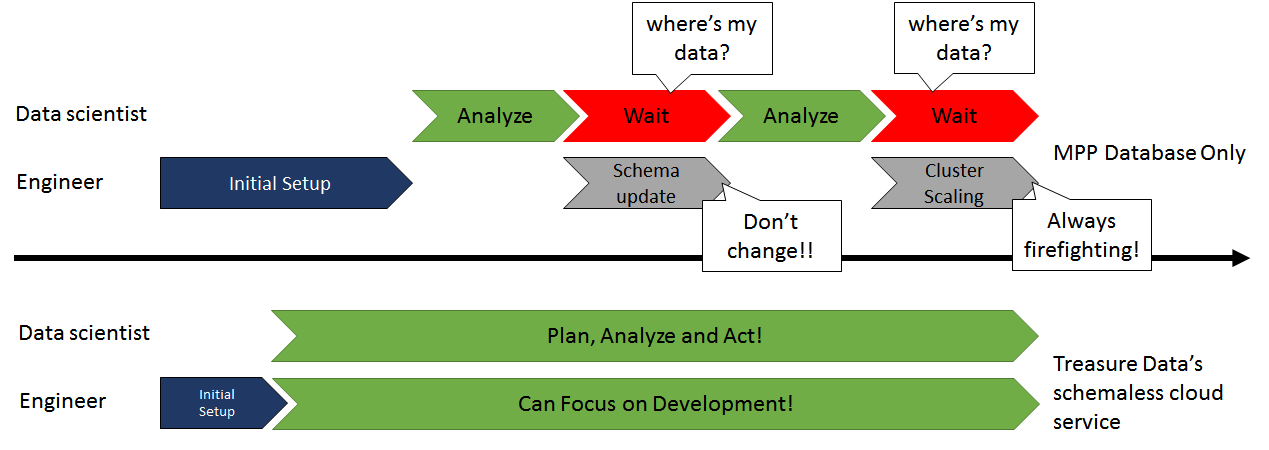
Eliminating Schema Management with Treasure Data
Some of Treasure Data’s customers migrated from a “Redshift only” setup to “Treasure Data + Redshift” setup. Treasure Data can ingest data as JSONs from many endpoints, and the data is stored in an efficient columnar format for SQL-based analysis. So, instead of landing data in S3 and copying it to Redshift, customers now stream the data to Treasure Data and use Treasure Data’s Redshift result output feature to periodically upload data to Redshift.
By having Treasure Data in front of Redshift, query downtime during schema updates has been eliminated: Because Treasure Data is schema-on-read, you can continue to query data even if data formats are changing.
Bonus: Easier Data Loading into Redshift
Loading data to Redshift from S3, especially in micro batches, requires careful operations (to learn more, see this best practices guide). At Treasure Data, we carefully studied various data load mechanisms and implemented a highly parallelized result output system for Redshift.

Let’s see it in action. Suppose you want to export five fields c1, c2, c3, c4 and c5 to Redshift from Treasure Data every hour. Then, it is as simple as writing “SELECT c1, c2, c3, c4, c5 FROM tbl” in our web console, and selecting Redshift as the output destination as shown below.
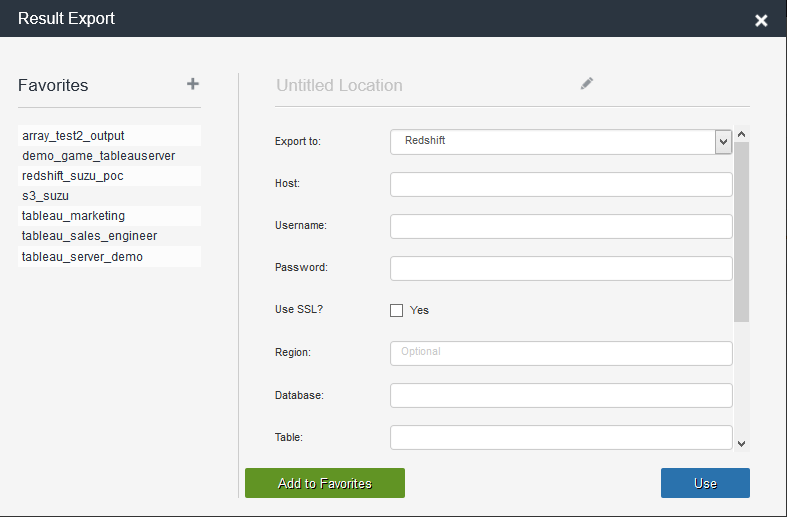
Notice that this output flow continues to work even if a new field is introduced upstream: the new data field, c6, is stored in Treasure Data but is not loaded into Redshift. If you want to include c6 as well, you can easily create a new Redshift cluster and use Treasure Data’s Redshift output feature with the statement “SELECT c1, c2, c3, c4, c5, c6 FROM t/l”.
Explore more benefits of the Treasure Data Service with our free 2-week trial or contact us to learn more about eliminating Redshift schema challenges by using Redshift + Treasure Data.