Why the Unified Logging Layer Matters
Why the Unified Logging Layer Matters
Why the Unified Logging Layer Matters
The amount of logs produced today is staggering. The logs provide opportunities for analysis to better understand customers and continually improve products. The log collection pipeline, then, becomes a source of valuable data.
Collecting and unifying the data for better consumption and analysis can be a challenge. It is important to understand the nuances of collecting log data and how open source software such as Fluentd can meet requirements will improve the data pipeline challenges in the long term.
To demonstrate, consider these three fundamentals in how we should think about collecting log data.
1. Logs must be consumable for machines first, humans second.
Humans are good at parsing unstructured text but read very slowly, whereas machines are the exact opposite — they are terrible at guessing the hidden structure of unstructured text but read very, very quickly.
At the end of the day, humans also need to read the logs occasionally to perform sanity checks. For that reason, the log format should cater to both, with the primary focus on machine consumption first and humans second.
While several formats are strong candidates (Protocol Buffer, MessagePack, Thrift, etc.), JSON is a strong contender because it is easy to read for both machines and humans. This is one decided advantage that JSON has over binary alternatives like Protocol Buffer.
2. Logs require reliable transport.
Collecting log data presents a challenge: Logs need to be transported from where they are produced (mobile devices, sensors, or web servers) to where they can be archived cost-effectively (HDFS, Amazon S3, Google Cloud Storage, etc.) for analysis.
Transporting massive quantities of logs over network creates a technical challenge. At minimum, the transport mechanism must be able to cope with network failures and not lose any data. Ideally, it should be able to prevent data duplication. Achieving this “exactly once” scenario is the holy grail of distributed computing.
3. Data inputs and outputs require ongoing attention and support
Today, collecting and storing logs is more complex than ever. On the data input side, increasingly more devices produce logs in a wide range of formats. On the data output side, developments in new databases or storage engines are frequently announced. Maintaining logging pipelines with so many data inputs and outputs is a challenge, and it must be addressed in a manageable way.
The Unified Logging Layer
I call the software system that meets the above three criteria the “Unified Logging Layer” (ULL). The ULL should be part of any modern logging infrastructure as it helps the organization to collect more logs faster, more reliably and scalably.
One implementation of the Unified Logging Layer is Fluentd, an open source project that Treasure Data sponsors and helps maintain. Fluentd addresses each of the three requirements of the Unified Logging Layer:
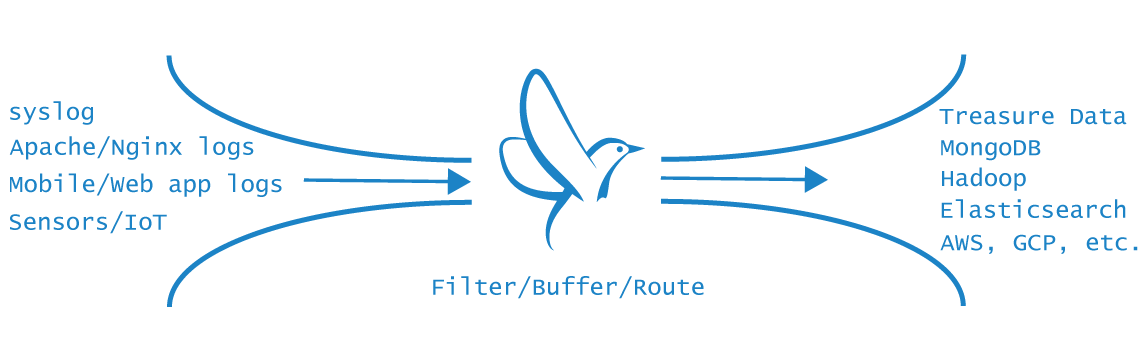
- Fluentd uses JSON as the unifying format.
- Fluentd ensures reliable transport through file-based buffering and failover.
- Fluentd implements all inputs and output as easy-to-contribute plugins.
If you are interested in learning more about Unified Logging Layer and Fluentd, check out the website and GitHub repository.