Apache Flink: General Analytics on a Streaming Dataflow Engine
Apache Flink: General Analytics on a Streaming Dataflow Engine
Apache Flink: General Analytics on a Streaming Dataflow Engine
This is a guest blog from Kostas Tzoumas, of dataArtisans and committer at Apache Flink.
Apache Flink® is a new approach to distributed data processing for the Hadoop ecosystem.
Flink’s approach is to offer familiar programing APIs on top of an engine that has built-in support for:
- Stream processing via pipelined execution, stream checkpointing, and mutable operator state
- Classic batch processing, including an optimizer and memory management
- Iterative processing for Machine Learning and other applications
- Stateful iterative processing, in particular for graph analytics
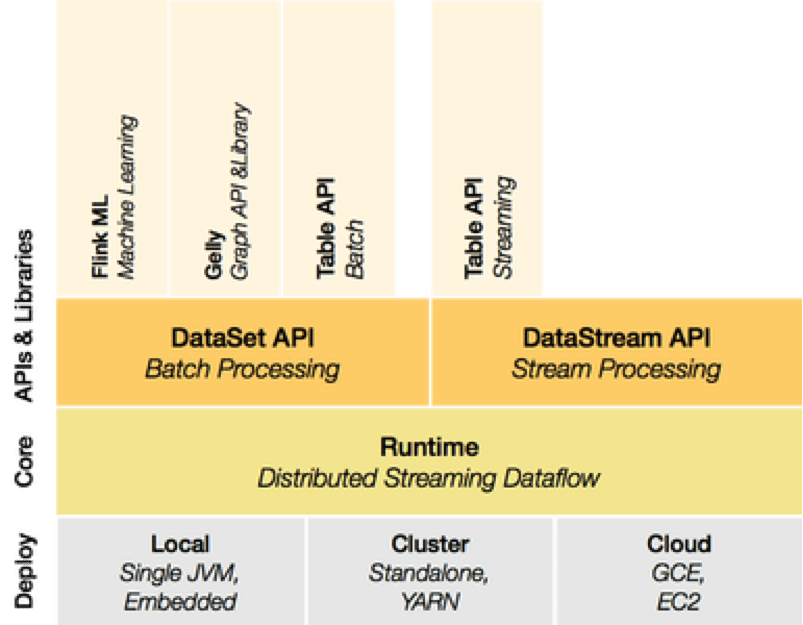
In order to natively support these workloads, Flink’s core is a streaming dataflow engine with support for iterations and delta iterations. On top of the streaming engine, the framework exposes a DataSet API for batch processing in Java, Scala, and recently Python, as well as a DataStream API for continuous stream processing in Java and Scala. On top of these API, Flink recently introduced built-in libraries for language-embedded logical queries (Table API), Machine Learning (FlinkML), as well as graph analytics (Gelly).
From early on, Flink introduced several innovative concepts in the open source world:
Batch on streaming
Flink’s runtime supports pipelined shuffles as well as (as of recently) blocked shuffles. This enables the system to natively execute both batch and streaming programs. In particular, at the runtime level, the system is agnostic to whether it is executing a batch or a streaming program. The differentiation is done in the higher-level compilation layers. You can read more on how Flink implements stream processing here.
Built-in iterations
Flink includes iterative dataflows with feedback as first-class citizens and exposes those in the APIs via its iterate operators. This makes the system very fast for ML and graph applications, as the system is aware that it is executing an iterative program and can make automatic decisions about data caching, as well as partially updating a cached result instead of recomputing it.
Optimization
All Flink DataSet programs pass through an optimization phase that generates executable plans, and makes cost-based (or rule-based in the absence of statistics) decisions on physical execution of joins, reducers, etc.
Memory management
From the beginning of the project, Flink has included a memory management component. System code (e.g., for sorting and hashing) operates (as much as possible) on binary serialized data that resides in managed memory. This reduces the garbage collection overhead and gives the system very robust performance both when data fits and when data does not fit in memory.
Flink’s origins
Flink has its origins in the Stratosphere research project. Flink joined the Apache Incubator in April 2014, and graduated as a Top-Level Project in December 2014. By now, Flink has more than 100 contributors from several organizations, making it one of the largest Apache Big Data projects.
Want to learn more?
With this blog post, we tried to shed some light on Flink’s design choices and unique technologies.
If you will be in the San Francisco Bay Area on June 17, come to the presentation by three founders of the Flink project (Robert Metzger, Stephan Ewen, Kostas Tzoumas) and committer Henry Saputra in Redwood City.
The event will be sponsored by Treasure Data: come have a beer on us and talk about streaming data!