Flink Fast
Flink Fast
Flink Fast
Back on June 17, Treasure Data hosted the latest round of the Silicon Valley Data Engineering meetup, “Apache Flink: Unifying batch and streaming modern Data analysis”. This meetup was organized in conjunction with the Bay Area Apache Flink Meetup .
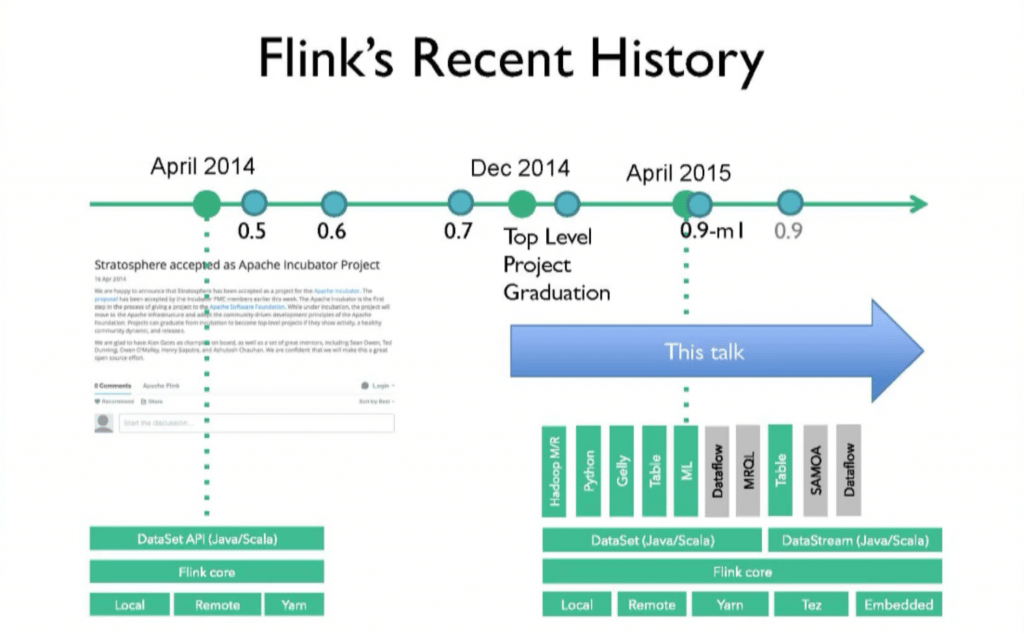
After the intro, Robert Metzger from Data Artisans kicked things off with a community update. He then walked through the history of Flink, in the process uncovering some of the rationale for the path its development and evolution have taken.
Following up, core Flink committer Kostas Tzoumas described the Flink execution model starting with a few key concepts:
- A program is a bag of operators;
- Operators = computation + state;
- Operators produce intermediate results = logical streams of records;
- Other operators can consume those.
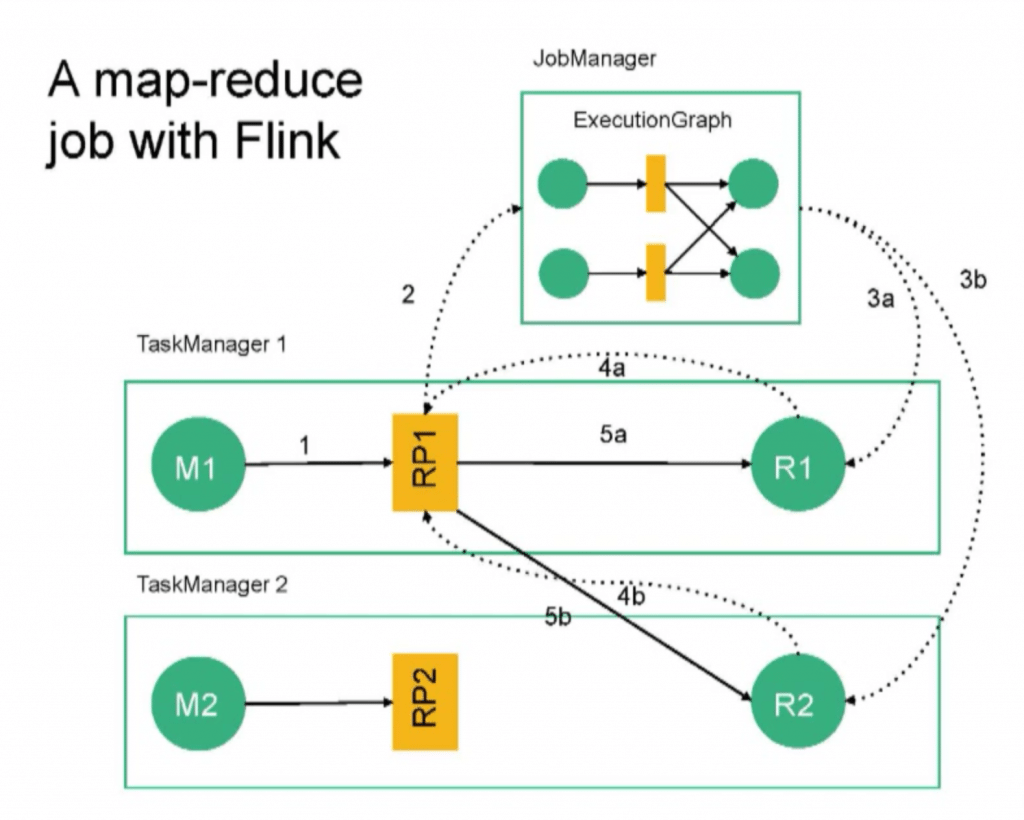
He went on to explain the basic (and later, detailed) architecture and concepts of a Flink job, then went on to show what a map-reduce job in Flink looks like, divided by task manager.
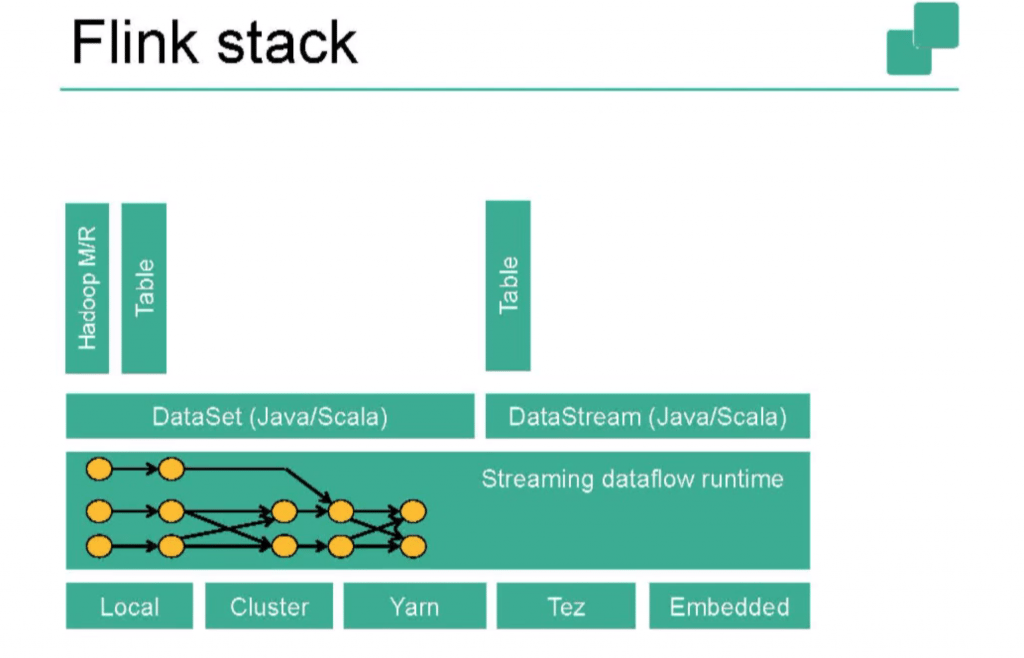
Finally, we learn about the Flink stack:
After some related questions, Stephen Ewen, committer and Vice President of Apache Flink and co-founder and CTO of Data Artisans, demoed a few key concepts on a running Flink system:
- Setting parallelism;
- Enabling checkpointing;
- Streaming data from generated source;
- Streaming data from Kafka;
- Testing throughput as the job is running.
For clarification, we are given a chalk talk on Kafka processing and checkpoints at the very end of the session.
Join us at the Silicon Valley Data Engineering Meetup!
There are more events coming in the Silicon Valley Data Engineering group! Next up: Fluentd, Docker and All That: Logging Infrastructure 2015 Edition on Thursday, July 23rd!