What’s the difference between Amazon Redshift and Aurora?
What’s the difference between Amazon Redshift and Aurora?
What’s the difference between Amazon Redshift and Aurora?
As you plan your analytics and data architecture on AWS, you may get confused between Redshift and Aurora. Both are advertised to be scalable and performant. Both are supposedly better than incumbents. Both have optically inspired names. So, what’s the difference?
In short, Redshift is OLAP whereas Aurora is OLTP. In this blog post, we’ll help clear up the confusion between OLTP and OLAP so that you can make the right choice between Aurora and Redshift.
What’s OLTP?
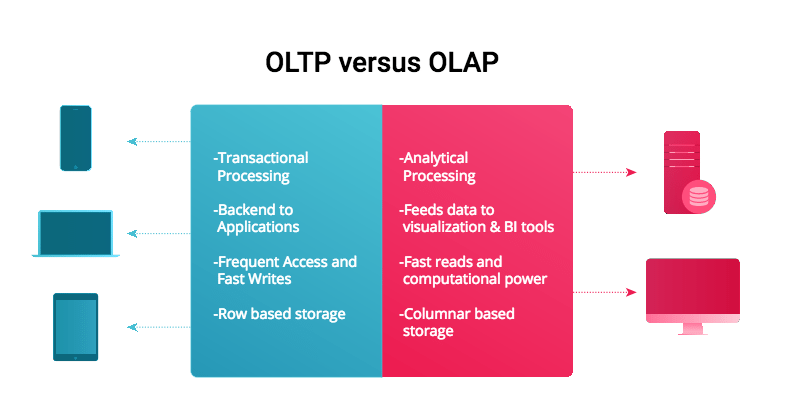
OLTP is what most people thinks of databases. It stands for Online Transactional Processing and is designed to serve as a persistent state store for front-end applications. They excel at quickly looking up specific information as well as transactional procedures like INSERT, UPDATE, or DELETE. Some common tasks asked of OLTP systems include situations like:
- What is the name of the current user, when given an email address?
- What is the last stage that a player was in for my mobile game?
- Update the billing addresses for a set of clients
These type of problems require a system that can look up and update one or more columns within one or many rows. The strength of OLTPs is that they support fast writes. A typical workload for OLTP is both frequent reads and writes, but the reads tend to be more of looking up a specific value rather than scanning all values to compute an aggregate. Common OLTP systems are:
- MySQL
- PostgreSQL
- Amazon Aurora
- Oracle RDBMS
- IBM DB2
What’s OLAP?
In contrast to an OLTP database, an OLAP database is designed to process large datasets quickly to answer questions about data. The name reflects this purpose: Online Analytic Processing.
Common use cases for an OLAP database are:
- What’s the customer lifetime value of my e-commerce application?
- What’s the median duration of play time for my mobile game?
- What’s the conversion rate for various landing pages based on the referrer?
An OLAP database is optimized for scanning and performing computations across many rows of data for one or multiple columns. To improve performance, OLAP databases are designed to to be columnar. Instead of organizing data as rows, the underlying data in an OLAP database is organized column by column. Columnar based storage allows for better compression and easier sequential reads, features necessary for scanning large amounts of data quickly.
Since OLAP is optimized for analyzing data, basic transactional procedures like writes or updates tend to be done in infrequent batches, typically once a day or an hour. OLAP shines when it comes to reads and analytical calculations like aggregation. Several well known OLAP systems are:
- Amazon Redshift
- HP Vertica
- Teradata
- IBM Netezza
- KDB+
Caution! Stop Abusing OLTP as OLAP
There’s a lot of confusion in the market between OLTP and OLAP, and due to the high price of commercial OLAPs, startups and budget-constrained developers have gone on to abuse an OLTP database as an OLAP database. The abuse falls into two categories:
- An often multi-shard MySQL database with application layer scripting to perform historical event data analysis. Although this setup is extremely common, it is one of the least productive ways to approach analytics. MySQL is not optimized in any way for reading large ranges of data and its support for analytic functions is weak. As there are multiple alternatives, avoid this “inexpensive” solution because you’ll be paying the price in other places eventually.
- Using PostgreSQL as an OLAP layer. This is a more legitimate choice than above for starting an analytics platform because of Postgres’s solid analytic User Defined Functions (UDFs). Also, thanks to its c-store extension, PostgreSQL can be turned into a columnar database, making it an affordable alternative to commercial OLAPs.
Finally, if you are considering moving from OLTPs abused as OLAPs to “real” OLAPs like Redshift, I encourage you to learn how to use Redshift’s COPY Command so that you can start seeing your data inside Redshift.