Customer Highlight: Ingesting Massive Volumes of Data at Grindr
Customer Highlight: Ingesting Massive Volumes of Data at Grindr
Customer Highlight: Ingesting Massive Volumes of Data at Grindr
Treasure Data helps a mobile app company capture streaming data to Amazon Redshift
![]()
Grindr was a runaway success. The first ever geo-location based dating app had scaled from a living room project into a thriving community of over 1 million hourly active users in under 3 years. The engineering team, despite having staffed up more than 10x during this period, was stretched thin supporting regular product development on an infrastructure seeing 30,000 API calls per second and more than 5.4 million chat messages per hour. On top of all that, the marketing team had outgrown the use of small focus groups to gather user feedback and desperately needed real usage data to understand the 198 unique countries they now operated in.
So the engineering team began to piece together a data collection infrastructure with components already available in their architecture. Modifying RabbitMQ, they were able to set up server-side event ingestion into Amazon S3, with manual transformation into HDFS and connectors to Amazon Elastic MapReduce for data processing. This finally allowed them to load individual datasets into Spark for exploratory analysis. The project quickly exposed the value of performing event level analytics on their API traffic, and they discovered features like bot detection that they could build simply by identifying API usage patterns. But soon after it was put into production, their collection infrastructure began to buckle under the weight of Grindr’s massive traffic volumes. RabbitMQ pipelines began to lose data during periods of heavy usage, and datasets quickly scaled beyond the size limits of a single machine Spark cluster.
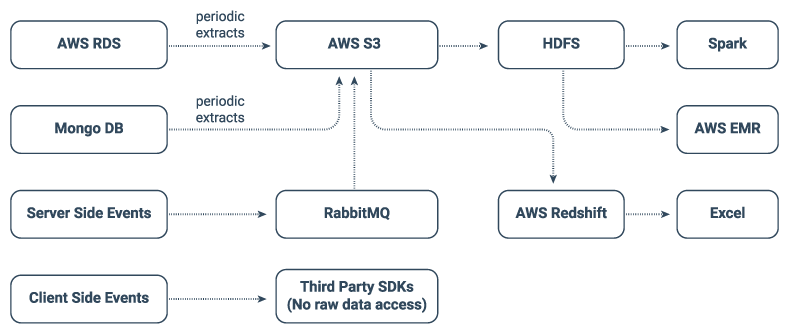 Original Architecture
Original Architecture
Meanwhile, on the client side, the marketing team was quickly iterating through a myriad of in-app analytics tools to find the right mix of features and dashboards. Each platform had its own SDK to capture in-app activity and forward it to a proprietary backend. This kept the raw client-side data out of reach of the engineering team, and required them to integrate a new SDK every few months. Multiple data collection SDKs running in the app at the same time started to cause instability and crashes, leading to a lot of frustrated Grindr users. The team needed a single way to capture data reliably from all of its sources.
During their quest to fix the data loss issues with RabbitMQ, the engineering team discovered Fluentd – Treasure Data’s modular open source data collection framework with a thriving community and over 400 developer contributed plugins. Fluentd allowed them to set up server-side event ingestion that included automatic in-memory buffering and upload retries with a single config file. Impressed by this performance, flexibility, and ease of use, the team soon discovered Treasure Data’s full platform for data ingestion and processing. With Treasure Data’s collection of SDKs and bulk data store connectors, they were finally able to reliably capture all of their data with a single tool. Moreover, because Treasure Data hosts a schema-less ingestion environment, they stopped having to update their pipelines for each new metric the marketing team wanted to track – giving them more time to focus on building data products for the core Grindr experience.
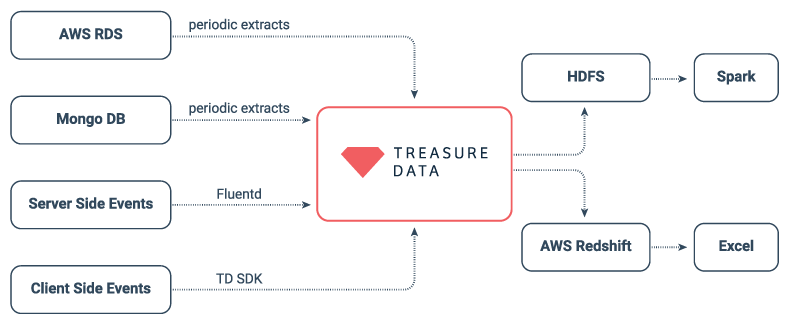 Simplified Architecture with Treasure Data
Simplified Architecture with Treasure Data
The engineering team took full advantage of Treasure Data’s 150+ output connectors to test the performance of several data warehouses in parallel, and finally selected Amazon Redshift for the core of their data science work. Here again, they enjoyed the fact that Treasure Data’s Redshift connector queried their schema on each push, and automagically omitted any incompatible fields to keep their pipelines from breaking. This kept fresh data flowing to their BI dashboards and data science environments, while backfilling the new fields as soon as they got around to updating Redshift schema. At last, everything just worked.