Build a Simple Recommendation Engine with Hivemall and Minhash
Build a Simple Recommendation Engine with Hivemall and Minhash
Build a Simple Recommendation Engine with Hivemall and Minhash
This is a translation of this blog post, printed with permission from the author.
In this post, I will introduce a technique called Minhash that is bundled in Treasure Data’s Hivemall machine learning library. Minhash is not usually thought of as a machine learning technique, but as you will see in this post, it’s quite useful. So without further due, let’s begin!
What is Minhash?
To explain Minhash, we must understand the Jaccard Coefficient first. The Jaccard coefficient measure how much two sets overlap one another. Please look below for an example and an equation:
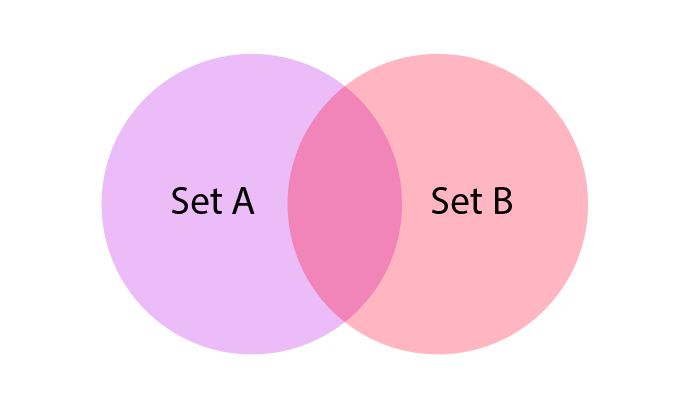
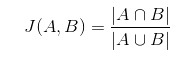
where J represents the Jaccard coefficient. The Jaccard coefficient of sets A and B is the ratio between the intersection and the union of A and B. In other words, “Out of all the combined elements in sets A and B, the ratio of the number of elements in common to both A and B” will be the Jaccard coefficient. The purpose of Minhash is to estimate this coefficient.
Why Not Just Count?
One might ask, “Isn’t the Jaccard Coefficient just about joining and counting across two sets? Why do we need to estimate it?”
Yes, you are right. However, there is a perfectly good use case for MinHash in Hivemall, which is when datasets A and B are large. You would need to run huge JOINs repeatedly and your computational cost becomes unrealistically expensive. Minhash gives us a very efficient way to estimate the Jaccard Coefficient where the exact computation might be too expensive to carry out.
Some Specific Examples
Let’s examine more specific use cases of Minhash.
The first well-known one is Data Management Platform (DMP).
Let’s say you want to optimize your marketing campaign by calculating how many visitors of two websites overlap. This kind of cross-tabulation is a popular use case for a DMP like us.
To be clear, the calculation itself is simple. However, when performed against websites with millions of visitors, the whole thing becomes quickly intractable and causes the DMP’s performance to deteriorate since it is prohibitively expensive. With Minhash, you can still calculate the set of users who visit the two websites, even if there are hundreds of millions of them.
The second example is recommendation.
Let’s say you have two products A and B. If the Jaccard coefficient between the purchasers of product A versus product B is very high, that is, if a high percentage of purchasers of product A also purchase B , then we should recommend product B to people who just purchased A.
But if there are products A, B, and C, would you recommend either product B or C to the purchaser of product A. You must compare the Jaccard coefficient of A and C with that of the Jaccard coefficient of A and B.
Now, imagine if you have 1,000 available products, or 10,000 products, which is very likely in a recommendation setting. Then you would want to use Minhash to speed up your Jaccard Coefficient calculations.
Minhash 101
Now let’s talk about how Minhash estimates the Jaccard Coefficient. Actually, please let me talk about it. This is what I wanted to talk about the most! Below is the figure shown earlier:
Let’s define:
- a is the total number of elements in set A
- b is the total number of elements in set B
- c is the total number of elements in the intersection of A and B
Then we can write:
![]()
Notice in the denominator, we double count the intersection of the sets, so then we subtract one of them back out.
Now, consider a hash function that maps elements of A and B to integers. Applying the hash function to each element of A, and define min(A) to be the minimum hash value.
Similarly, we apply the same hash function to all the elements of set B to find its hash minimum: min(B).
What is the probability P(A, B) that min(A) = min(B)?
This turns out to be same as “The element in A∪B corresponding to min(A∪B) is contained in A∩B” (The mathematically inclined reader: the proof is left as an exercise)
That is,
![]()
Wait! So the Jaccard coefficient J(A, B) can be estimated by the probability that the min(A)=min(B)!
Therefore, we can prepare multiple different hash functions and compute P(A, B) to estimate J(A, B). For example, let’s run this 10,000 times. If in 100 of those iterations that min(A) = min(B) then J(A, B) = 100 / 10,000 which equals 0.1. Similarly if we run 5,000 iterations of the function, and in 1,500 iterations the min(A) = min(B) then J(A, B) = 1,500/5,000 = 0.3.
In other words, without having to do any JOIN between two sets,one can estimate the overlap ratio between the two sets.
Running Minhash in Hivemall
Finally, let’s try running this in Hivemall.
The following tutorial is the recommended method for using Minhash in Hivemall. So let’s start by running a query.
Preparing Data
We will use the famous sample dataset, news20, for this example. The first three lines are below:
| Article ID (id) | Word Count (words) |
|---|---|
| 1 | [“197:2″,”321:3″,”399:1″,”561:1″,”575:1″,”587:1”,…] |
| 2 | [“7:1″,”1039:1″,”1628:1″,”1849:1″,”2686:1”,”2918:1″…] |
| 3 | [“77:9″,”137:1″,”248:1″,”271:1″,”357:1″,”377:3”,…] |
Where:
- Article ID: the article identifier
- Word Count: the number of times that word (identified by word id) was used in the article. Ex: word 197 was used twice, 321 was used three times, etc
There are 15,935 articles worth of data containing the word counts of each article.
Articles with the same words are more likely to have the same or similar content.
So if two articles have similar content, wouldn’t it may be a good recommendation to give a reader who has read the first article to read the second article? This is the problem we’ll be solving.
Let’s look for which articles are alike using Minhash. It should be noted that we are just taking into account “how many times a word is used” and not looking at “which words are being used”.
Calculate the minimum value of the hash value
Let’s create a table with some of the data from news20.
Running the query below which applies the hash function to the words in each article, it will return the minimum value of that article.
Note that by putting the option “-n 100”, we will be running 100 random hash functions.
SELECT MINHASH(id, Words, "-n 100" ) as (clusterID, rowid) -- " '- n 100' option to use the 100 hash function" FROM news20;
And we will save the results in a table named “news20_minhash”.
| Article ID (id) | Minimum of hash value (cluster_id) |
|---|---|
| One | 896574361 |
| One | 320726648 |
| … | … |
| Two | 1726436972 |
| Two | 1103952875 |
| … | … |
| Three | 1406179360 |
| … | … |
Since I ran the hash function for 100 iterations, there are 100 rows for each article ID. Remember that we originally have 15,935 articles worth of data, so in total, there will be 15,935 x 100 = 1,593,500 records returned in total.
Aggregating the Results
Onto the next query, which will find which articles are similar to other articles.
SELECT J.Rowid, Collect_set (rid) AS Related_article
FROM (
SELECT L.Rowid, R.Rowid AS rid, count (*) AS cnt --number of matched minhash values
FROM news20_minhash l LEFT OUTER JOIN news20_minhash r ON (L.Clusterid = R.Clusterid) --only keep records where the minhash matched
WHERE L.Rowid != R.Rowid -- Exclude articles where the ids are the same
GROUP BY l.rowid, r.rowid
HAVING cnt > 10 --exclude results that have less than 10 matches
) J
GROUP BY J.Rowid
ORDER BY J.Rowid ASC
We limit the results to those with more than 10 matches in line 14, which means we are only interested in results where the Jaccard coefficient is greater than 0.1. Any article with a Jaccard coefficient less than 0.1 would not be considered similar enough to make the recommendation.
The results of the above query can be seen below:
| Article ID (id) | Similar Articles (related_articles) |
|---|---|
| 2 | [10022,282,7422,10402] |
| 4 | [3764,4884,664,10364] |
| 6 | [7146] |
| … | … |
Each row pertains to an article and the articles with similar content to that article are stored in an array using their ID number. In our sample dataset, it just happened that articles 1, 3, and 5 all did not have any similar articles.
Nonetheless, you would be able to give article recommendations from this method and it only takes two queries to produce!
Postscript
Minhash is a Randomized Algorithm
We mentioned at the beginning that Minhash is not a technique in the field of machine learning. Minhash is an example of a randomized algorithm, a technique that uses randomness and probability theory for implement efficient algorithms.
Matrix Factorization > Minhash fro Recommendation
In this post, I showed how to use Minhash to implement a recommendation system because everyone is familiar with recommendation and Minhash can be applied rather neatly to it.
That said, if you wish to properly implement a recommendation engine in Hivemall, Matrix Factorization is a better technique to use. The developers of Hivemall wrote a tutorial on how to conduct Matrix Factorization in Hivemall.
b-Bit Minwise Hashing
Minhash was originally established during the 20th century. More recently, it has evolved and improved to a technique called b-Bit Minwise Hashing. The basic idea remains the same.