Elasticsearch, and How to Make it Faster for ALL Queries
Elasticsearch, and How to Make it Faster for ALL Queries
Elasticsearch, and How to Make it Faster for ALL Queries
With millions of downloads since launch, Elasticsearch has become the open-source tool of choice for full text search. Also, it has become increasing popular for analytics use cases thanks to its ease of setup and JSON-based RESTful API.
Like any other technology, however, Elasticsearch excels in some areas more than others. For example, JOINs are somewhat clunky, and Pipeline Aggregations, Elasticsearch’s take on window functions, is fairly new. To be fair, the community will address many of these limitations in due course, both through code and evangelism, but for now, Elasticsearch can use a complementary system to deliver the full spectrum of analytical requirements.
And this is how Treasure Data complements Elasticsearch with its new integration.
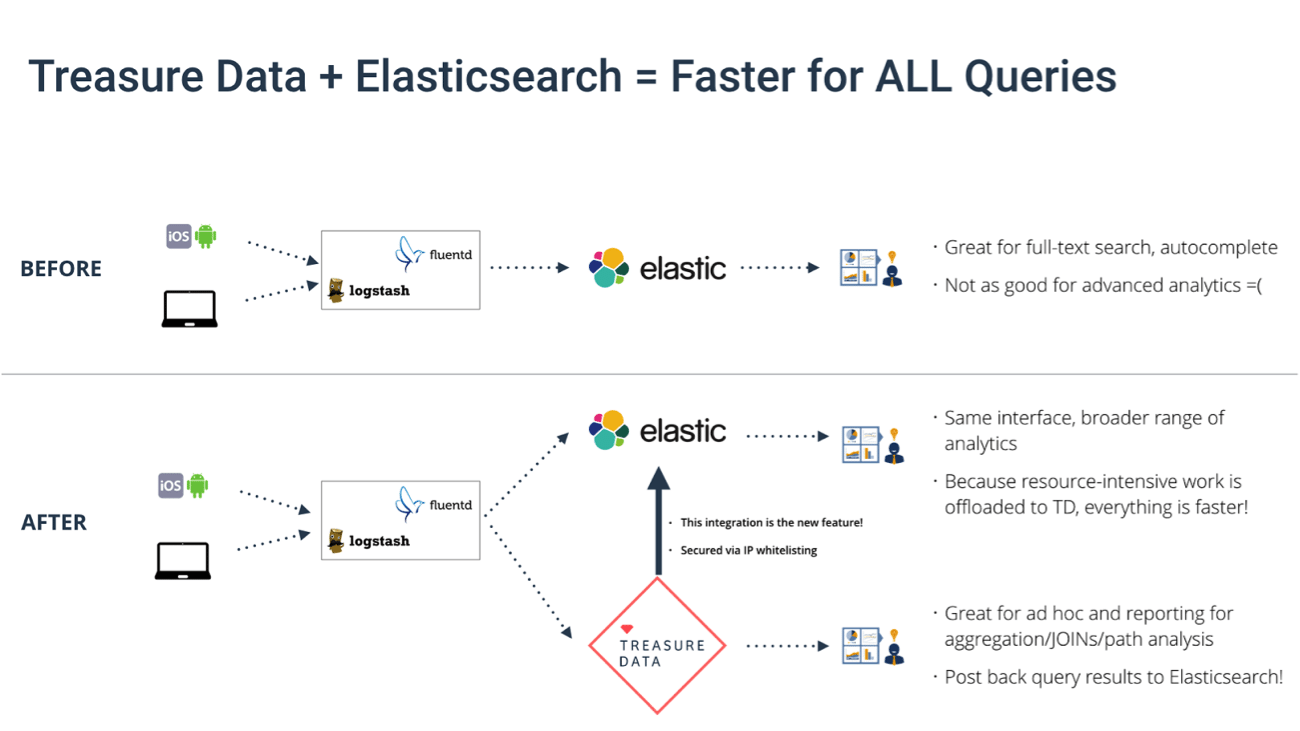
Treasure Data has an SQL interface that you can use for batch queries (Hive) or use to run ad-hoc queries (Presto). It supports JOINs and window functions. Hivemall, our Machine-Learning-on-SQL library, bring machine learning to a business analyst’s fingertips. Best of all, you can post Treasure Data’s query results back to Elasticsearch and visualize it with Kibana.
How to Get Started
To learn how result export Treasure Data query results to Elasticsearch, check our documentation. For those new to Treasure Data, we give you a straightforward service to ingest, analyze, and export results to the data store or visualization tool of your choice – including Elasticsearch. Why not get started today?
We created a press release to announce the news. Check it out!