The Magic of Presto: Petabyte Scale SQL Queries in Seconds!
The Magic of Presto: Petabyte Scale SQL Queries in Seconds!
The Magic of Presto: Petabyte Scale SQL Queries in Seconds!
If you’ve been in the data analytics field for even a short period of time, you’ve probably at least heard of Spark, Hive or maybe Cloudera Impala as a means of running SQL-type queries against large semi-structured datasets. One you may not have heard about though, is Presto.
Originally developed at Facebook, Presto allows querying data where it lives and can be up to an order of magnitude faster than Hive. This is why Treasure Data and Teradata have both become key contributors to the Presto open source project.
In our webinar, on Thursday, February 25th, we’ll join Teradata’s Kamil Bajda-Pawlikowski (Chief Hadoop Architect and Presto contributor) to discuss why Presto is recently emerging as a de-facto engine for fast, distributed, ad-hoc queries at companies including Facebook and Netflix? We’ll learn:
- What is Presto?
- Presto Features
- Presto Architecture and Internals
- Presto in Production: Some real-world use-cases
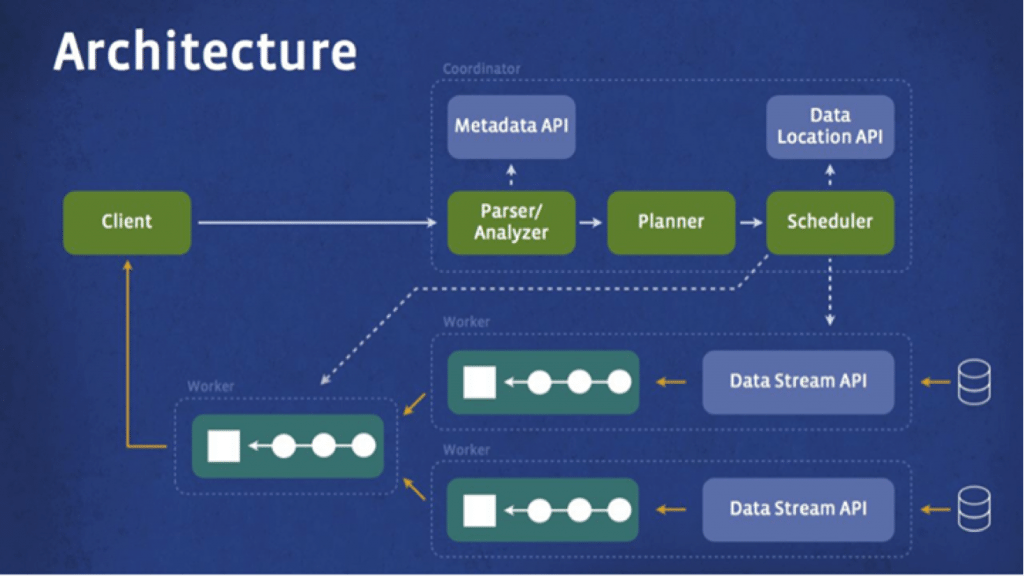
Why does this matter? Because understanding where Presto fits into the ‘NoSQL’ paradigm will help you make the kinds of decisions to optimize your data-analytics ecosystem. Did you know:
- That Presto is optimized for ad-hoc queries of large data sets, where Hive is better suited to batch queries?
- That Presto runs almost entirely in memory, making it possible to run million-row queries in seconds?
- That Presto is extensible through an ecosystem of plug-ins aimed to aggregate data (in a single SQL query) from multiple sources?
- That, among other open source options, Presto was chosen for its ease of code readability and maintainability?
Learn that and a lot more at our webinar, The Magic of Presto: Petabyte Scale SQL Queries in Seconds. We look forward to seeing you next Thursday morning!