The Analytics & Data Science Hierarchy of Needs
The Analytics & Data Science Hierarchy of Needs
The Analytics & Data Science Hierarchy of Needs
Inspired by Maslow’s Hierarchy of Needs, I wanted to create a similar idea around data science and analytics. Too many times do I see individuals putting the cart before the horse and trying to build a complex predictive analytics pipeline when they don’t even know the basics of their customer’s usage and behavior.
Just like in Maslow’s model, each lower stage is a necessary foundation for the stages above it. If that foundation is weak, the higher stages may crumble and leak even if they initially work. Resources for building each stage involve a combination of human talent and the right set of tools for your needs.
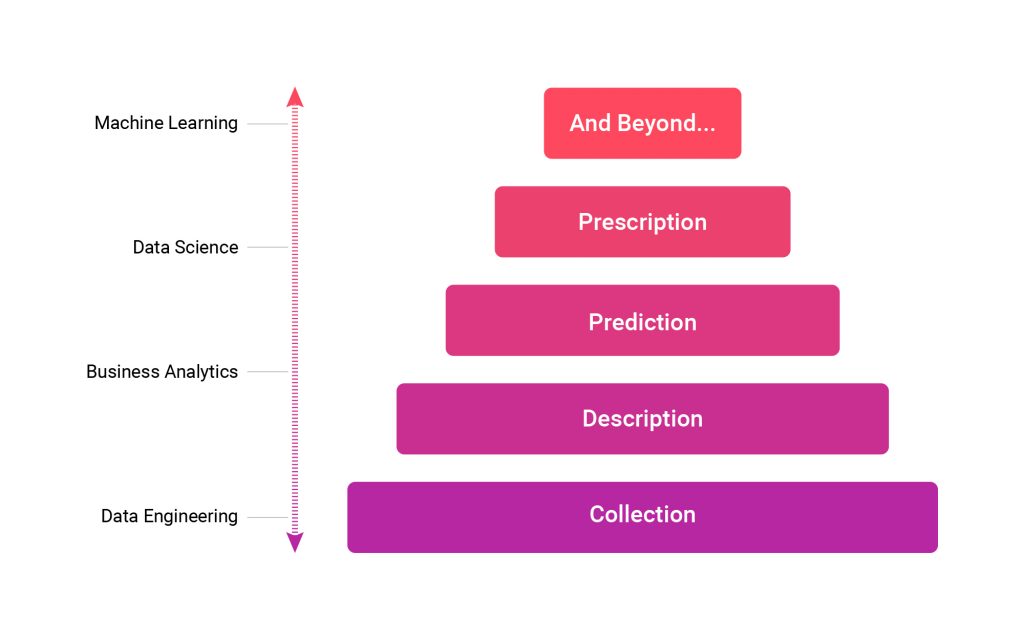
Collection
For a robust data pipeline, you want access to clean, reliable data. Think of data collection like a faucet. Ideally, you want crystal clear water that is ready to be consumed at any time. However, if the pipes are old and rusty or the water source is contaminated, the water coming out is either undrinkable or you must attach a filter to clean it before use.
Data works the same way. In most cases, the original data source needs multiple levels of cleaning to become useful. At this stage of analytics, your heroes will be the data engineers and data architects who will build those clean and smooth running pipelines. Tools like Fluentd and Embulk enable software engineers to easily build data collection into their applications. For more details about building a strong data collection foundation, check out InsideBIGDATA’s article about building a robust analytics initiative..
Description
Once you have a consistent stream of clean data, you need to have a clear understanding of the data’s composition. Descriptive statistics is where you look into the past and ask questions that have concrete answers to them.
- What is the average time my users stay on the homepage?
- How many customers bought products x and y together?
- How often does garbage collection happen on my servers?
These types of questions have straightforward numerical answers and form the building blocks of more complex analysis. They also tend to monitored regularly by both analysts and decision makers to follow trends and usage. Even today, dashboards continue to rule business analytics. Tableau and Google Analytics continue to be popular, but younger companies like Mixpanel and Looker are seeing growth.
As the business world becomes more data intelligent, we’re seeing a shift to where anyone, regardless of title, is able to calculate descriptive statistics. It’s not just data analysts or data scientists anymore, the responsibility is falling to anyone with data access, from business analysts to product managers.
Prediction
Thanks to the success of Netflix Amazon, and Pandora’s recommendation engines, predictive analytics has generated a lot of excitement. As a result, many companies have jumped into predictive analytics, many of them too early or with inappropriate resources.
To get the most out of predictive analytics, you need the foundation built by a good data ingestion system and a strong understanding of your data. Moving to the predictive requires data scientists with more specialized skills and software engineers who implement the models the data scientists build.
Luckily, it’s easier than ever to get started on predictive analytics thanks to a wealth of resources available. If your organization has a solid data engineering foundation, applying machine learning techniques to get predictions isn’t too difficult. Multiple analytics products, such Datameer or Microsoft’s offerings, are baking in predictive solutions.
Prescription
Still in it’s infancy, prescriptive analytics are the next wave of data science. Where prediction was about looking into the future, prescriptive analytics is about offering guidance. We’ll be able to ask questions and have multiple solutions returned to us. Prescriptive analytics combines all available resources from statistics and computer science such as machine learning, computer vision, natural language processing, and Bayesian statistics.
Prescriptive analytics are beyond what the average company can implement or even need. It’s in a proof of concept phase with leaders like Google and certain industries paving the way. For the majority of companies at this time, prescriptive analytics are more of a wish rather than a want or need. It’s something to keep up to date on and see where prescriptive analytics might fit in your data initiative in the future.
And Beyond…
So what’s next? An exciting sneak peek into what’s possible is Google’s AlphaGo. For the first time, an AI has successfully beaten a human competitor at the game of Go. Artificial Intelligence and machine learning are reaching a stage we expected to reach in ten more years. The brilliant data scientists, software engineers, and computer scientists that work in both academia and enterprise are breaking down the divide between academic research and business, allowing us to surge ahead with breakthroughs. Additionally, with competitions like Kaggle and the economic drive of obtaining the next best algorithm, anyone can now take part to the expansion of this field.
So where does your company stand? Are you struggling to get predictive insights because you haven’t built a solid pipeline? Or did you build a good foundation and are entering into analytics in a confident manner? No matter where you are today, make sure the decisions and plans for tomorrow’s analytics initiatives are built with an appropriate foundation to build on.