A Self-Study List for Data Engineers and Aspiring Data Architects
A Self-Study List for Data Engineers and Aspiring Data Architects
A Self-Study List for Data Engineers and Aspiring Data Architects
With the explosion of “Big Data” over the last few years, the need for people who know how to build and manage data-pipelines has grown. Unfortunately, supply has not kept up with demand and there seems to be a shortage of engineers focused on the ingestion and management of data at scale. Part of the problem is the lack of education focused on this growing field.
Currently, there seems to be no official curriculum or certification to become a Data Engineer or Data Architect (that we know of). While that’s bad news for companies that need qualified engineers, that’s great news for you! Why? Because it’s basic supply and demand and data engineers and data architects are cleaning up! In fact, we did a little research and found that the average salary for a data engineer is around $95.5k. While the salaries for data architects average around $112k nationally, the main path to this strategic, coveted position (and salary) means cutting your teeth as a data engineer and working your way up or making a lateral job move.
What does it take to start getting a piece of this action? Don’t worry: we did research on that, too! 🙂 We did a survey of a pool of ‘Data Engineer’ and ‘Data Architect’ job ads on LinkedIn and GlassDoor and ranked the top 20 sought after job skills. They are:
| SQL | 65% |
| Python | 60% |
| Data Pipelines | %55 |
| Data Warehouse | %50 |
| Hadoop | %45 |
| Hive | %45 |
| ETL | %40 |
| Spark | %40 |
| AWS | %30 |
| Redshift | %30 |
| Java | %25 |
| Kafka | %25 |
| MapReduce | %25 |
| Ruby | %25 |
| Scala | %25 |
| Vertica | %25 |
| Data Quality | %20 |
| JavaScript | %20 |
| NoSQL | %20 |
| Statistics | %20 |
Percentage of times these skills showed up in data-related job descriptions
Keep in mind that most job ads (and recruiters) are behind the curve on invoking new technology, (where’s Fluentd?!?! What about ELK Stack?) because recruiters and HR typically get their information second hand. Plus, cutting-edge technology typically enjoys a period of minimal adoption while it is being tried out.
If you’re starting from the beginning, and set an end goal to become a data architect, the first step is to learn the skills of the data engineer. While this article won’t – and can’t – completely connect the dots for you, our aim is to get you thinking about this actively and starting to look for yourself in the right direction.
Roles in a Data Organization
So what are the roles in a data organization?
Data Engineers are the worker bees; they are the ones actually implementing the plan and working with the technology.
Managers (both Development and Project): Development managers may or may not do some of the technical work, but they help to manage the engineers. Project managers help handle the logistical details and time-lines to keep the project moving according to plan.
Data Architects are the visionaries. They lead the innovation and technical strategy of the product and architecture. Highly experienced and technical, they grow from an engineer position. Very experienced and valuable, they are rare ducks since they’ve essentially been working in this field since its beginning.
When we surveyed several ‘Data Architect’ job descriptions on Glassdoor, LinkedIn and Indeed.com, we found many similarities to the skills required of Data Engineers, so let’s focus on the differences. The differences include things like coaching and leadership; data modelling, and feasibility studies. Another thing required of architects is a firm grasp of legacy technologies. Typically, “legacy” technologies mentioned include: Oracle databases, Teradata, SQL server and Vertica. In the resources below, we don’t cover much of these because there’s extensive documentation on them already.
The Data Pipeline, described
In order to understand what the data engineer (or architect) needs to know, it’s necessary to understand how the data pipeline works. This is obviously a simplified version, but this will hopefully give you a basic understanding of the pipeline.
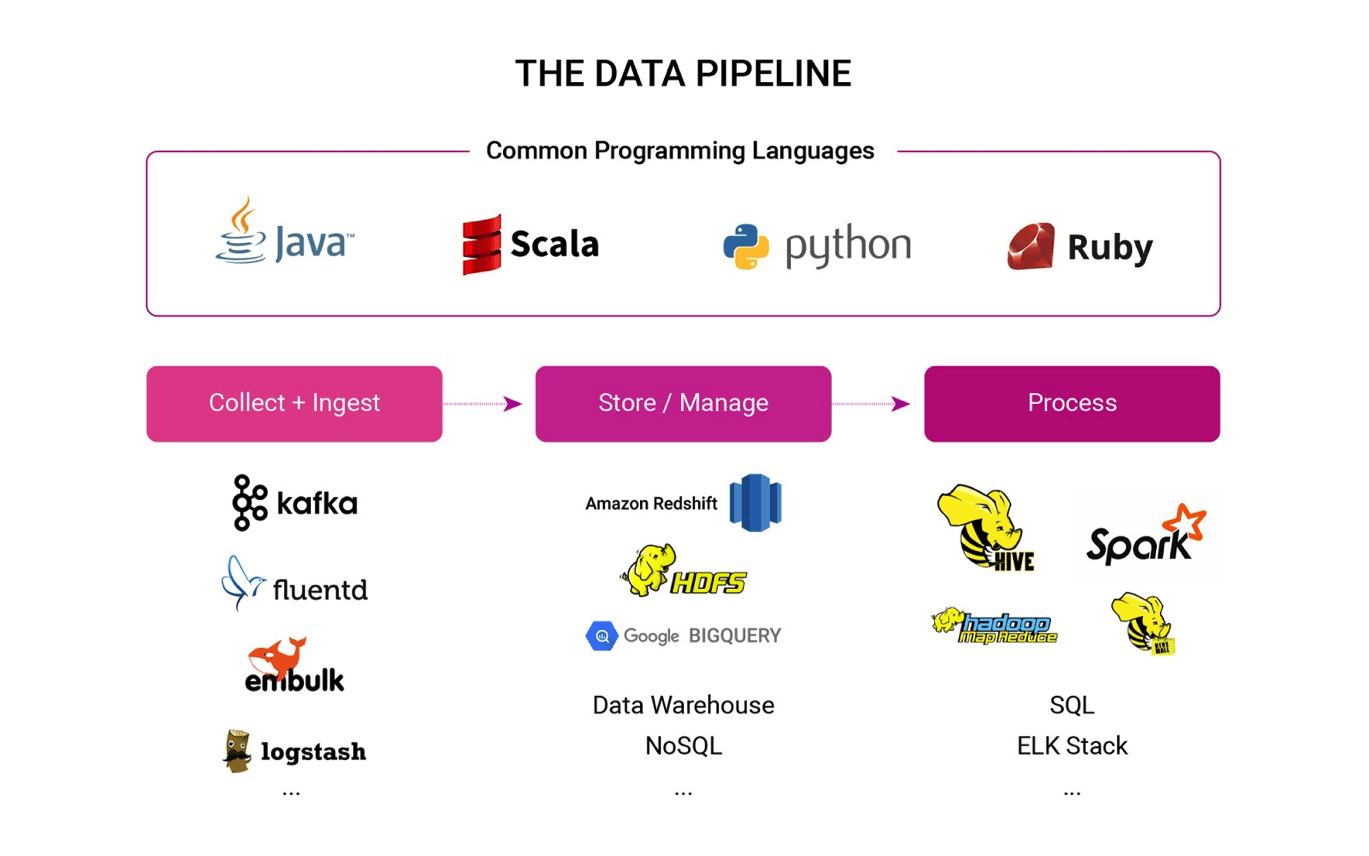
Common programming languages are the core programming skills needed to grasp data engineering and pipelines generally. Among other things, Java and Scala are used to write MapReduce jobs on Hadoop; Python is a popular pick for data analysis and pipelines, and Ruby is also a popular application glue across the board.
Collection and ingestion are tools at the beginning of the pipeline. Common open-source examples are: Apache Kafka, Fluentd and Embulk. This stage is where data is taken from sources (among them applications, web and server logs, and bulk uploads) and uploaded to a data store for further processing and analytics. This upload can be streaming, batch or bulk. These tools are far from the only ones; many dedicated analytics tools (including Treasure Data) have SDKs for a range of programming languages and development environments that do this.
Storage and management are typically in the middle of the pipeline and take for form of Data Warehouses, Hadoop, Databases (both RDBMS and NoSQL), Data Marts and technologies like Amazon Redshift and Google BigQuery. Basically, this is where data goes to live so it can be accessed later.
Data processing is typically at the end of the pipeline. SQL, Hive, Spark, MapReduce, ELK Stack and Machine Learning all go into this bucket and are used to make sense of the data. Are you querying your data into a format to use for visualization (like Tableau, Kibana or Chartio)? Are you formatting your data to export to another data store? Or maybe running a machine learning algorithm to detect anomalous data? Data processing tools are what you’ll use.
The point is, when you see a job ad or recruiter referring to a specific technology, make it a goal to understand what the technology is, does, and what part of the data pipeline it fits into.
The List
We’ve compiled a partial list of articles, books, links and guides that we hope you will find useful in your data engineering/architecture endeavors. We’ve included some background information, as well as information on each piece of the data pipeline.
Since the data field is constantly evolving, many of these articles should be viewed as informed opinions rather than absolute fact, so please use these as guideposts only.
Given that data architecture and data engineering is meant to support data science efforts within an organization, we’ve included a few resources on this as well. As always, if there is something missing from this list, please make suggestions in the comments.
Happy Studies!
Background Reading
Milton and Arnold. Introduction to Probability and Statistics. McGraw Hill, 1995. ISBN 0-07-113535-9 A primer on probability and statistics, which forms the foundation for data science.
The Data Science Handbook: http://www.thedatasciencehandbook.com/#get- the-book “A compilation of in-depth interviews with 25 remarkable data scientists, where they share their insights, stories, and advice.”
Quora: How do I learn big data: https://www.quora.com/How-do-I-learn-big-data-1 A very good overview, from a quora thread, on the “what” and “how” of big data. Mentions some slightly older tech than what we’ve previously covered here (including Mahout, Oozie, Flume and Scribe) but the same concepts still apply.
Skills of the data architect: http://www.captechconsulting.com/blogs/skills-of-the-data-architect A slightly older article, from 2013, which includes the more generic and ‘soft’ skills required of the data architect.
Quora: data architect vs analyst vs engineer vs scientist: https://www.quora.com/Whats-the-difference-between-a-data-architect-data-analyst-data-engineer-and-data-scientist A quora discussion among data scientists comparing the three disciplines.
Data Collection and Ingestion
Python for aspring data nerds: https://blog.treasuredata.com/blog/2015/04/24/python-for-aspiring-data-nerds/ A very basic example of an application (this one written in python) that contains basic data ingestion (event) code. The article demonstrates a very basic data pipeline through ingestion, storage and processing.
Logs are the Lifeblood of your data pipeline: http://radar.oreilly.com/2015/04/the-log-the-lifeblood-of-your-data-pipeline.html A O’Reilly blog from our very own Kiyoto Tamura which explains logging (with fluentd) as the basis for data collection for analytics.
How Luigi works: http://help.mortardata.com/technologies/luigi/how_luigi_works “Luigi is a Python-based framework for expressing data pipelines.” An excellent explanation, including basic concepts, from Mortar (now Datadog).
Embulk: https://github.com/embulk/embulk “Embulk is a parallel bulk data loader that helps data transfer between various storages, databases, NoSQL and cloud services.”
Kafka Guide: http://get.treasuredata.com/Kafka-Guide/ and https://docs.treasuredata.com/articles/fluentd-consumer-for-kafka Two guides – the first of which explains how to set up different instances of the well-known open source message broker, Apache Kafka; and the second of which shows you how to set up sending analytics events from it.
What every engineer should know about real time data: https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying A good, thorough explanation of logging and its relation to data storage.
Data Storage
Data Lake overview: http://martinfowler.com/bliki/DataLake.html More and more, big data efforts are less concerned with the Data Warehouse and its structured data requirement, and more interested in the Data Lake, which can handle raw data.
Hadoop overview: https://blog.pivotal.io/pivotal/products/demystifying-hadoop-in-5-pictures A down-to-earth explanation of Hadoop.
NoSQL cheat sheet: http://www.dummies.com/how-to/content/nosql-for-dummies-cheat-sheet.html Compares different NoSQL technologies.
NoSQL guide: http://nosqlguide.com/ A blog containing some informative articles on different aspects of NoSQL technologies.
SQL vs NoSQL overview: https://www.digitalocean.com/community/tutorials/understanding-sql-and-nosql-databases-and-different-database-models An explanation of some of the key differences between SQL and NoSQL data stores.
Public cloud data-store comparison: http://gaul.org/object-store-comparison/ Compare cost, durability, and region support of public cloud object stores, e.g., Amazon S3. You can select to columns in the comparison.
Data Processing
Amazon Redshift guide: https://www.periscopedata.com/amazon-redshift-guide Periscope’s Lazy Analyst guide to Amazon Redshift
Excel to SQL with lifetime customer value: https://blog.treasuredata.com/blog/2014/12/05/learn-sql-by-calculating-customer-lifetime-value-part-1/ Learn SQL by Calculating Customer Lifetime Value. Part 1 of a two-part series.
Quora: what’s the benefit of SQL: https://www.quora.com/What-is-the-benefit-of-learning-SQL/answer/Kiyoto-Tamura Even in the world of ‘Big Data’, SQL is still a fundamental building block of how we use data.
Intro to Pandas: http://www.gregreda.com/2013/10/26/intro-to-pandas-data-structures/ Learn all about Pandas Data Structures. Part 1 of a 3-part series.
Using SQL and R to do funnel analysis https://blog.treasuredata.com/blog/2016/01/25/using-sql-and-r-to-do-funnel-analysis-part-1/ Learn how to do funnel analysis within a working data analytics pipeline. Part 1 of a 2-part series.
Processing data with Jupyter and Pandas: https://blog.treasuredata.com/blog/2015/06/23/data-science-101-interactive- analysis-with-jupyter-pandas-and-treasure-data/ An end-to-end tutorial on processing data through a data pipeline using python and Jupyter notebooks on the front end.
Data processing and data pipeline overview: http://flowingdata.com/ A must read on not just data processing, but all things data pipeline, using R programming language.
Python data visualization libraries: https://www.dataquest.io/blog/python-data-visualization-libraries/ A bit more on python’s data visualization libraries.
Hadoop vs Elasticsearch: https://blog.treasuredata.com/blog/2015/08/31/hadoop-vs-elasticsearch-for-advanced-analytics/ A good breakdown of two leading technologies in the big data space.
Common Programming Languages
Python 101: http://learnpythonthehardway.org/book/ A beginner’s (hands-on) primer for the python programming language.
Book: McKinney, Wes. Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython. O’Reilly, 2013. ISBN-13: 978-1449319793 “..a practical, modern introduction to scientific computing in Python, tailored for data-intensive applications.”
Python and Spark intro: http://www.kdnuggets.com/2015/11/introduction-spark-python.html A hands-on, quick introduction to Python with Spark.
Using Java with Hadoop: http://www.coreservlets.com/hadoop-tutorial/ A high-level tutorial of Java with Hadoop, including Java’s HDFS API.
Like this sort of thing? Then check out the Data Science Reading List. Also watch this spot in the future for our upcoming posts that will help you get started with much of the technology discussed here.