We Analyzed Over 6 Million SQL Queries & Here’s What We Found
We Analyzed Over 6 Million SQL Queries & Here’s What We Found
We Analyzed Over 6 Million SQL Queries & Here’s What We Found
As part of our effort to improve product usability, I decided to take a look at how other analysts and Treasure Data users write their SQL. Like any other language, you can develop your own style over the years, and we should design our query editor accordingly to make the query-authoring experience on Treasure Data more enjoyable.
Initially I was curious about what kinds of errors others encounter. In a past life, I taught a corporate training class writing SQL to engineers and product managers. Teaching that class taught me the usual difficulties new users encounter learning SQL. But what about more experienced users? Are they like me, who seems to never spell ‘DISTINCT’ correctly or forgets a GROUP BY clause when investigating iteratively? My excuse is I’m typing too fast.
Initial Results
After sectioning out failed queries from my initial set, I wanted to only grab errors that were man made and from ad-hoc queries. Using Presto’s error handling definitions, I separated errors into “User Based” and “Other.”
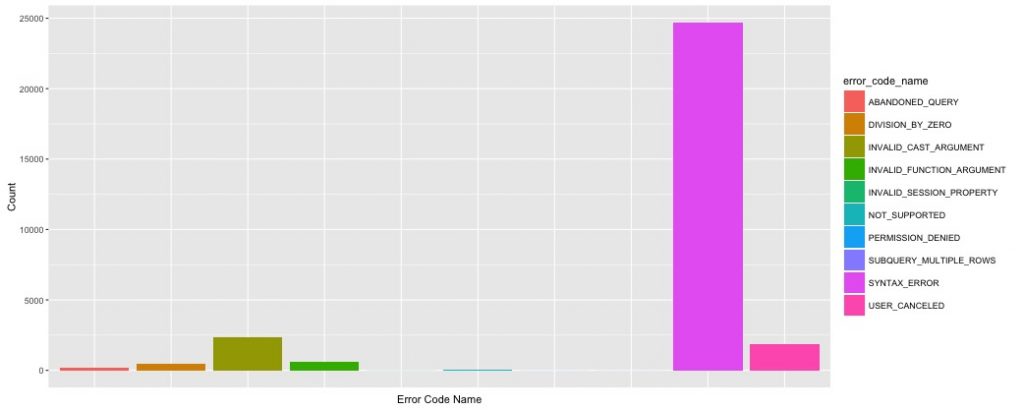
For one month of data:
- There were around 6.34 million Presto queries run.
- Of those, just over 30,000 queries failed due to user error.
- 82% of those user errors were defined as syntax errors.
- Also interestingly, our Presto defines a user canceled query as an error.
Parsing Error Messages
So what were the most common syntax errors? This was a bit more tricky to find. Presto does give a failure message for each error, but grouping these messages into anything useful takes a bit of string wrangling and regex. First, I needed to remove any potentially sensitive information, like table and column names, from the messages. The output of the resulting regular expressions left me with a message skeleton that were much more favorable to grouping.
However, even after that, I was still left with over 50 different messages. Based on my knowledge of SQL, I decided to group what I felt like were similar errors together. For example, I grouped the errors associated around correct identification of tables together because that suggests the user forgot their table name, how to spell it, or that they created one. I also grouped all errors associated with the GROUP BY clause together. These included errors like not including the clause when using aggregation functions and not including the correct columns in the clause.
Common syntax errors fell into similar buckets:
- About a quarter of the errors relate to misspelling or misnaming columns, tables, and functions
- Around 12% of errors came from misunderstanding of key SQL concepts, like aggregations, unions, and joins
- Explicit syntax errors, such as missing or misplaced brackets, accounted for almost 10% of the errors
- 8% of errors were due to unexpected parameters in a function
- Various type casting errors made up around 5% of all errors
The graph below shows the top ten most common types of errors
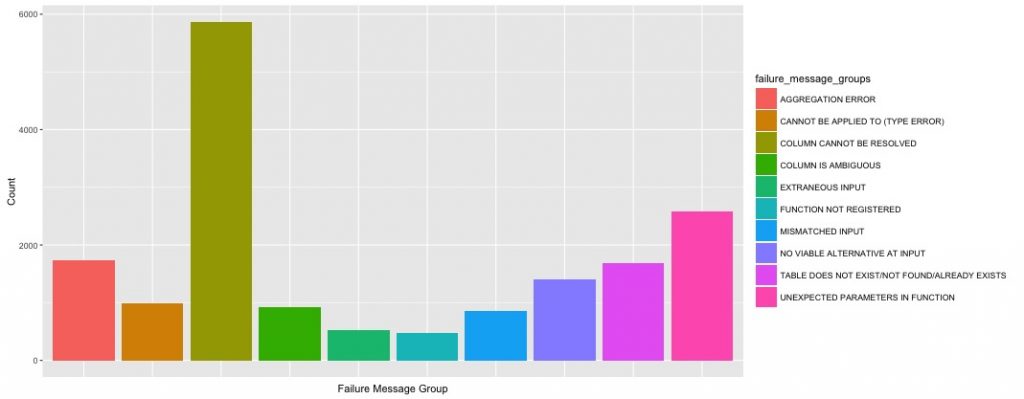
With almost 6,000 occurrences, the most common error was “COLUMN CANNOT BE RESOLVED.” This is a nice way of saying: “You misspelled or forgot the name of the column.” One of the more innocent of all the errors. It’s easy to type too fast and not spell check before running the query.
However, the second and third most common errors are a bit more insidious. Seeing “UNEXPECTED PARAMETERS IN FUNCTION” in second place reminds me of when I taught my SQL class. This kind of error happens when users don’t understand a function’s usage or assume the SQL function is similar to another programming language’s function. It shows a carelessness to look up easily found documentation.
Additionally, aggregation errors were quite common to see in my class and are still common for more experienced users. The concept of aggregation can be difficult for newer users to get their head around since it involves the user to conceptualize data on a row basis, when most people naturally think of data as a set of columns.
A running theme of the most common errors is that they are surprisingly easy to fix. Misspellings, function definitions, and missing parentheses can all be fixed by having a good development environment. Coming soon to Treasure Data is our new console that will offer a more comprehensive and intuitive SQL IDE. As I’ve been using the new console myself, I find that I’ve been making fewer mistakes. I can iterate more quickly on my analyses, and get to my answers faster. Though, I am going to miss laughing at myself for typing “DISTINCT” as “DISTNCT” for the tenth time in a day.