Announcing Treasure Workflow
Announcing Treasure Workflow
Announcing Treasure Workflow
We want to give companies the same power to collaborate and manage data they now enjoy in the world of software. That’s why we’re excited to announce the launch of Treasure Workflow. Treasure Workflow is the first multi-cloud workflow engine that can orchestrate tasks not only on Treasure Data, but across a variety of cloud infrastructures such as AWS and Google Cloud Platform.
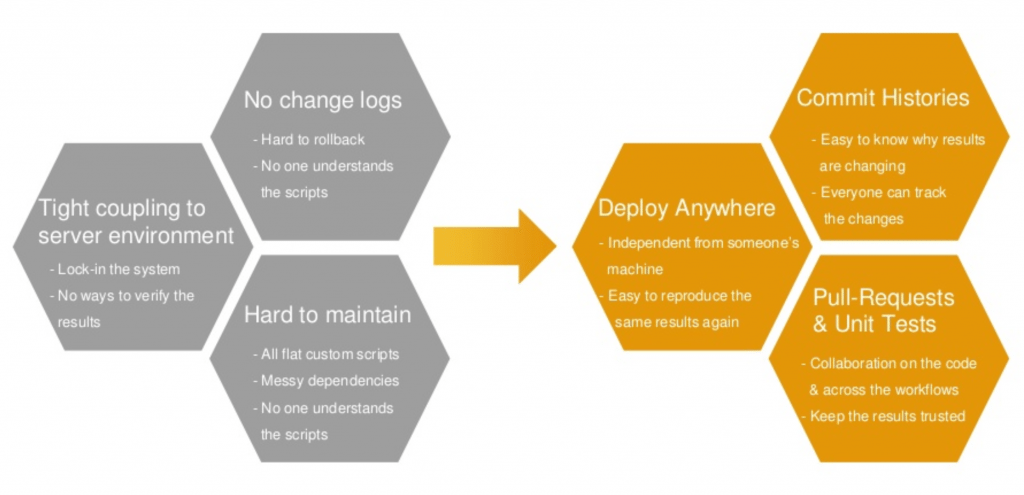
Treasure Workflow brings software best practices to the development of data applications, e.g. smart retargeting, A/B testing with custom goals, and omnichannel marketing. Some of these business applications can involve hundreds of steps, each of which may require complex transformations or dependencies, with customer and transaction data spread across a large variety of on-premises databases and cloud-based systems.
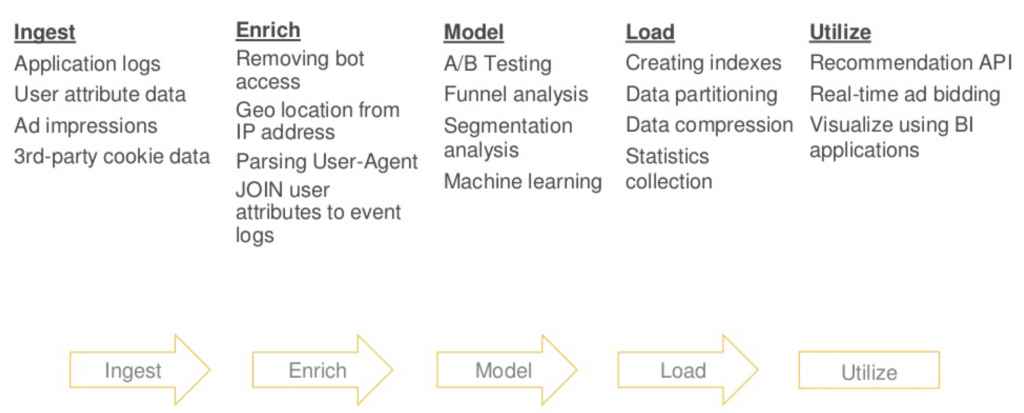
When data workflows are this complex, the challenges of management and collaboration become huge. CRON scheduled jobs may run in an unexpected order and may require “smart retries” when the data required for particular steps take longer to process than expected. Some steps might need to be triggered only when certain data is available. And with all this logic embedded in scripts, figuring what does what can become so difficult that troubleshooting is near-impossible.
In place of this tangle of confusion, Treasure Workflow brings clarity and simplicity. Treasure Workflow is a language-agnostic engine that enables you to define analytics processing recipes separate from the underlying code, data, and environment. Now you can:
- Parameterize Modules. Rather than one gigantic, ungainly script, Treasure Workflow allows you to break queries into manageable, well-identified modules, to aid in collaboration, updates, and maintenance.
- Group Tasks. Enable query writers to specify dependencies easily, without having to slog through hundreds of lines of code to make a change.
- Automate Validation. Verify results in between steps of a complex query to ensure that as data changes, we can trust the results.
Treasure Workflow has already made waves among our beta users like Packlink. A fast-growing parcel delivery platform, as Packlink’s sales exploded, so did the complexity of their data workflows. Their data pipelines became brittle, requiring constant monitoring and maintenance. More and more of their analysts’ precious time was consumed trying to get the data they needed, rather doing analysis.
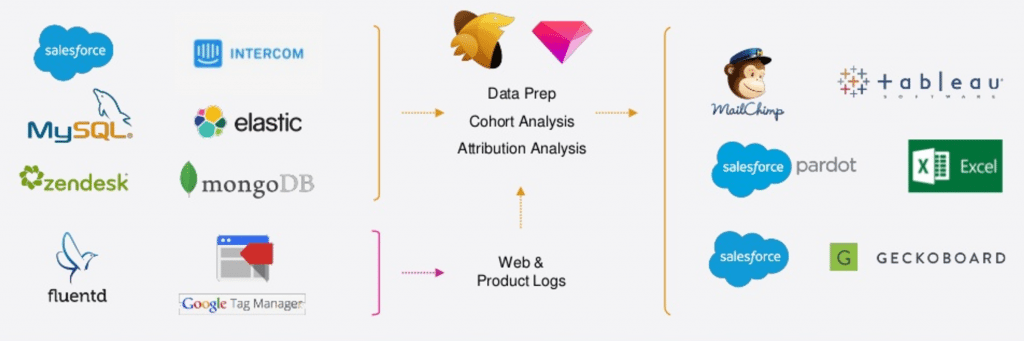
When Packlink became a Treasure Data customer, the ability to centralize their data and construct timed queries greatly eased this burden. But Treasure Workflow took it to another level. With Treasure Workflow, Packlink was able to convert their carefully timed scheduled jobs into robust, reusable workflows.
Today, all of Packlink’s analytics pipelines are fully automated. The difference this has made in their customer data analytics is remarkable. “I now feel more confident in my ability to manage complex analytic flows,” says Pierre Bévillard, Packlink’s Head of Business Intelligence. “From ETL processes for transferring data, to attribution or cohort analysis, to deploying these insights back into the cloud systems my company uses to run our business. It has enabled us to get out more timely refreshes of these insights for our analytics consumers—Sales, Marketing, and the executive suite. I can feel confident each night our analysis will be completed as expected.”
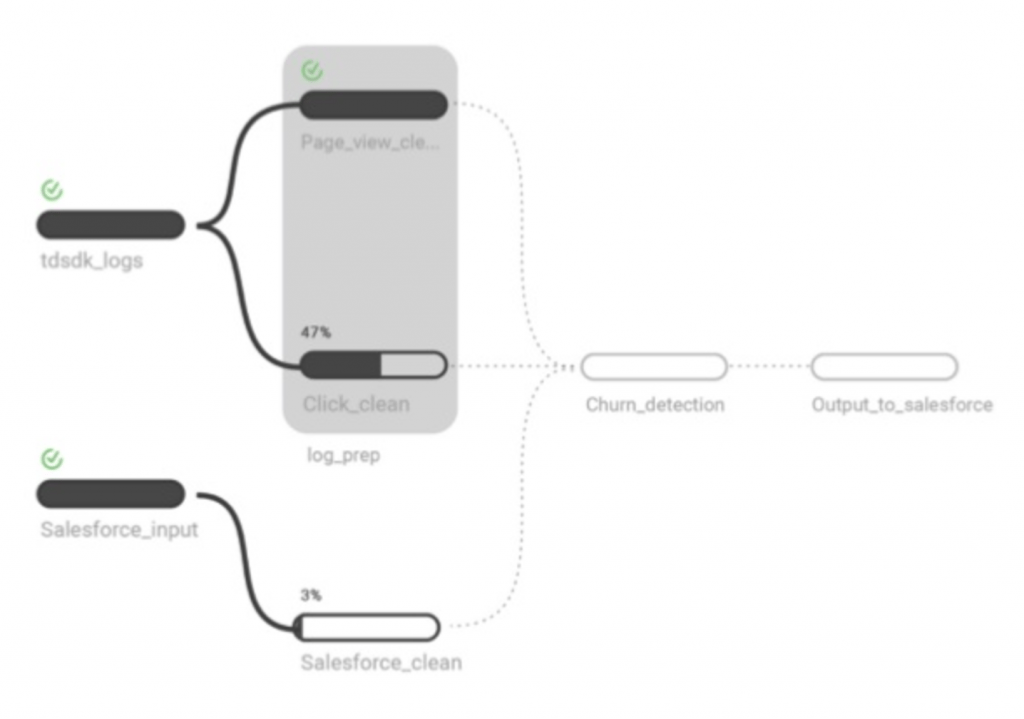
We are proud to make Treasure Workflow a part of our Live Data Management platform. It is the enterprise version of our open source product DigDag, developed as part of our continuing support of open source software development. If you’d like to find out more about Treasure Workflows, feel free to schedule a free demo today.