How We Make Customer Support Seamless Using Treasure Data
How We Make Customer Support Seamless Using Treasure Data
How We Make Customer Support Seamless Using Treasure Data
The Treasure Data enterprise Customer Data Platform (CDP) helps the digital marketer segment audiences for vastly better personalization by uniting siloed data to achieve a 360° view of the customer. Marketing teams have been able to increase their KPIs and enjoy ownership of the data platform in ways never before possible. But marketers aren’t the only ones enjoying a better life in the united states of data.
In this blog post, I introduce another use case for the Treasure Data CDP that seamlessly and efficiently improves our customer support. This is how we sync data between systems to enable the automatic triggers for support even when some data are missing and/or needs unification.
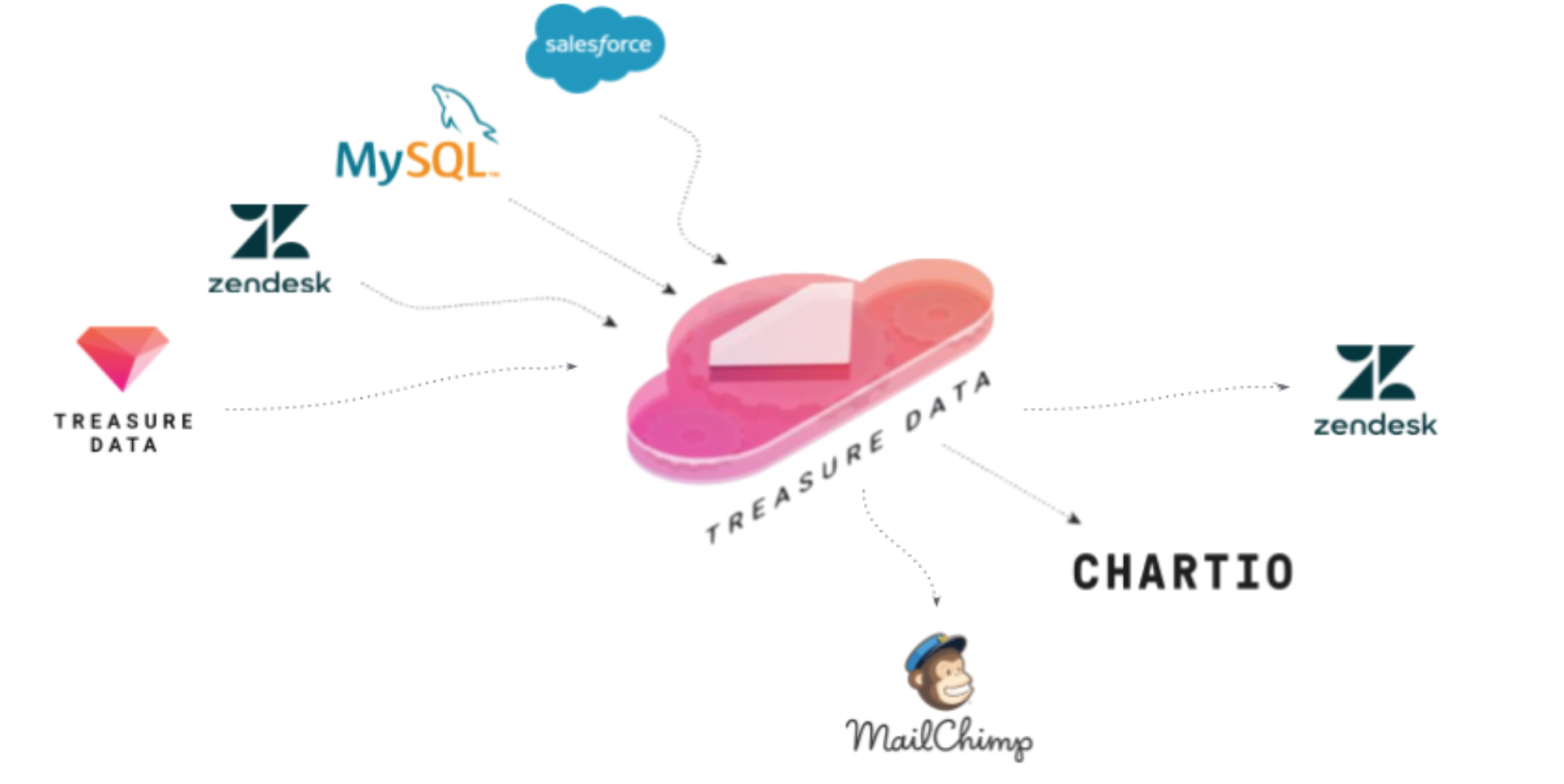
Background: Treasure Data’s Customer Support Model
Treasure Data Support uses Zendesk for support ticket management to provide Email / Chat / Support Form to our customers. (If you are our customer, you might have chatted with us before.) We are on Salesforce for customer relationship and account management.
In order to deliver great support to our customers, we want to know a requester’s background, such as their pricing plan, computing resources and subscription status quickly when we receive a request.
Furthermore, in Treasure Data, there are several customer roles defined to represent their particular deployment phase; sales, solution architect, or customer success. Our support is always available for all customers even if they are in the early stage of on-boarding with their solution architect. Thus, we handle support tickets based on a customer’s status. If you are on-boarding Treasure Data, your solution architect should know all conversations between the support team and you, our customer.
Enabling Zendesk’s Trigger for Information Sharing
Simply said, we want to do the following actions when we receive an inquiry:
- Case 1
Transfer the inquiry to the sales rep and the solution architect automatically if a user belongs to an account under contract less than 3 months. - Case 2
Transfer an inquiry to the customer success rep automatically if a user belongs to an account near the contract renewal. - Case 3
Alert a service level agreement (SLA) when an emergency ticket from a user belonging to specific contract plan is received.
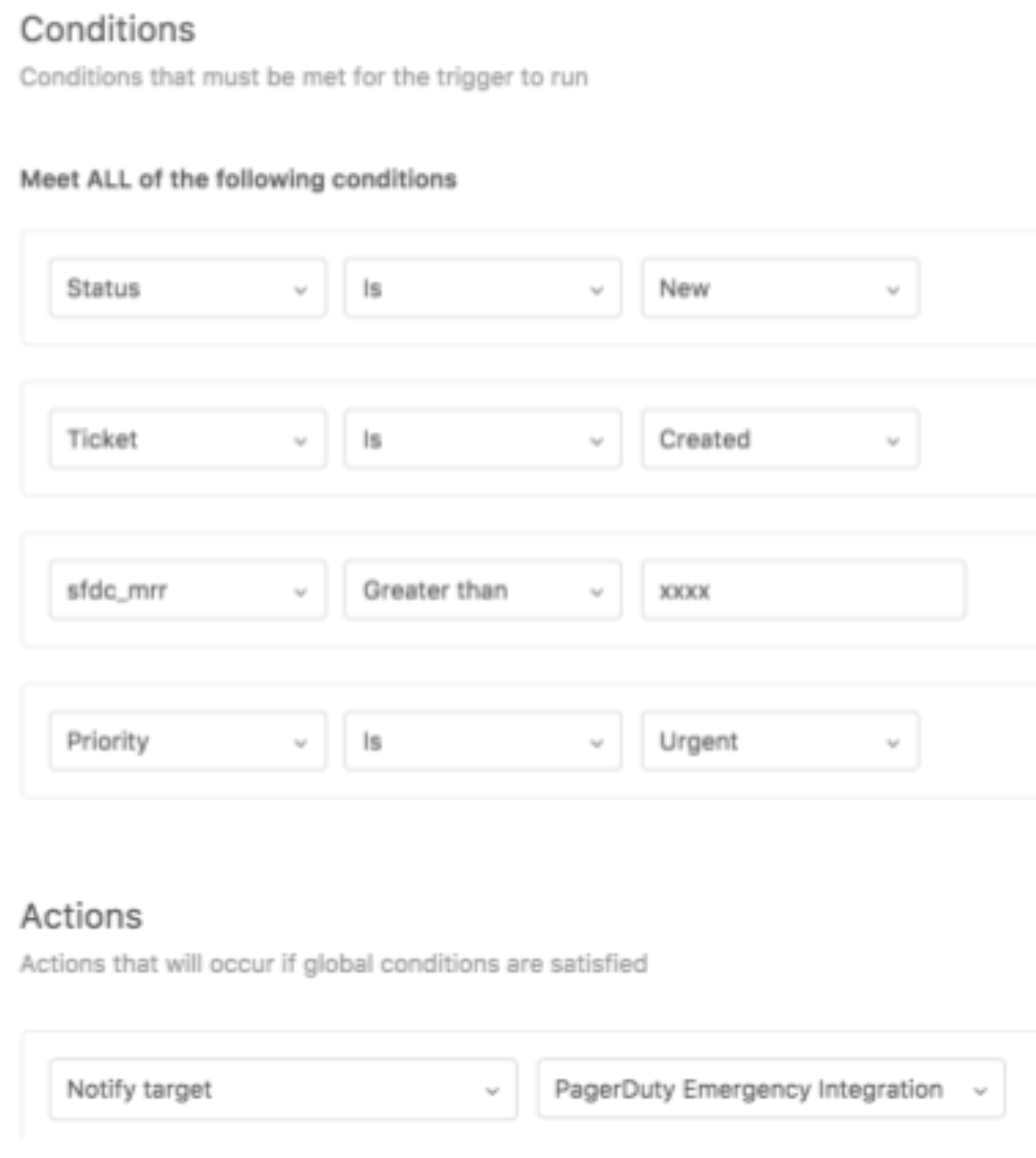
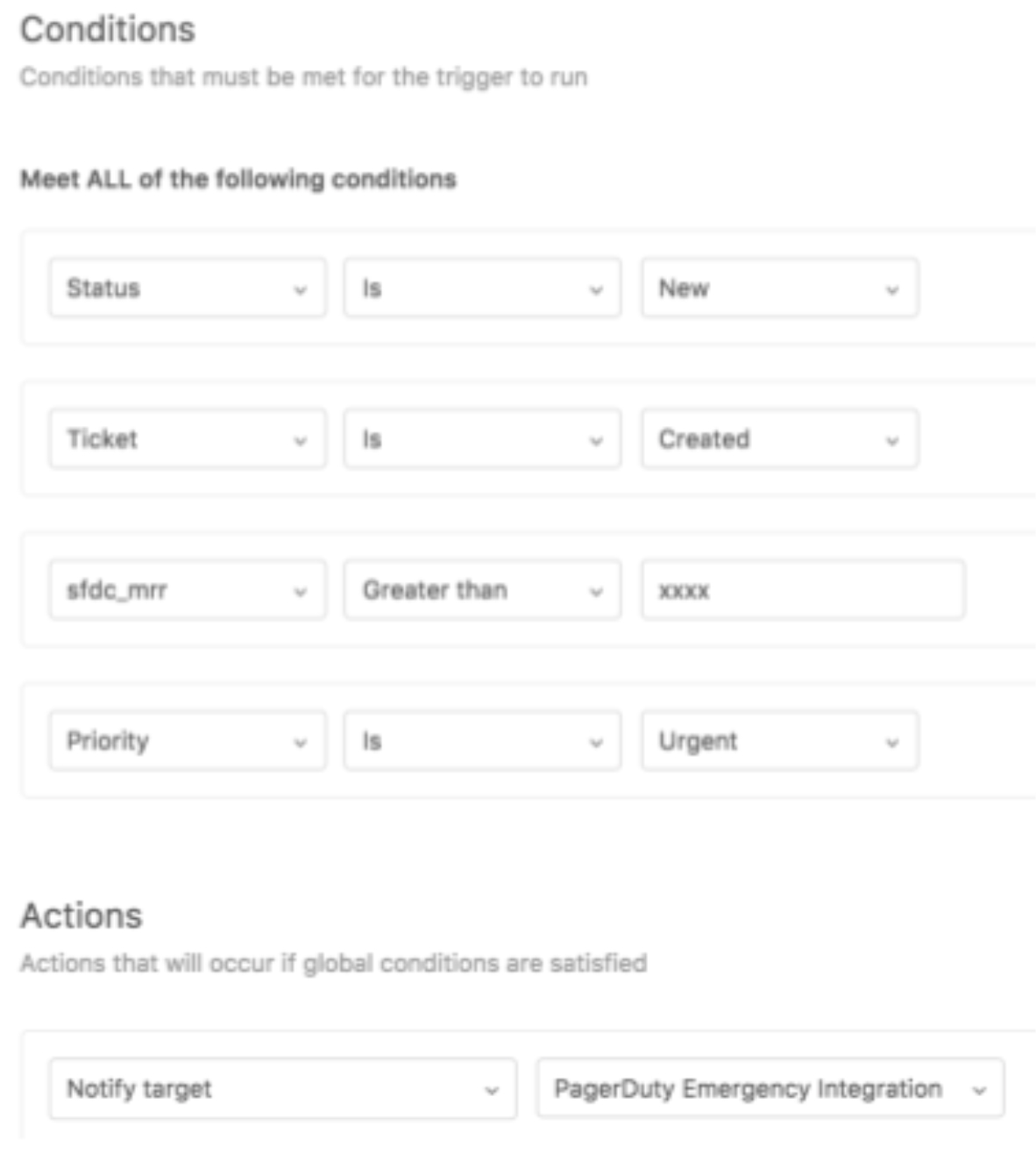
For example, in Case 3, the trigger setting in Zendesk can be as follows:
“sfdc_mrr Greater than xxxx”.
In order to run the trigger in Zendesk based on contract information such a “sfdc_mrr” in Salesforce, we have to sync data between Zendesk and Salesforce.
Build Support KPI Dashboard
Zendesk has a built-in KPI dashboard, which is called Zendesk Insights, to see how several KPIs related to support works. But, it’s difficult to dig into KPIs associated to a user activity based on the following conditions:
- Customer’s Support Activities per MRR Basis
- Customer’s Support Activities per Sales Rep
Also, we’d like to share such a usage to the Treasure Data sales team via email.
Problem: Sync data between Zendesk, Salesforce, Chartio
In order to complete these goals, the following data sync issue between Zendesk and Salesforce is present:
- Zendesk User is based on an email basis, but SFDC is managed on an contract basis. We couldn’t link email between Zendesk User and SFDC Contract.
- Even if we use the Zendesk SFDC add-on, there were a lot of cases where the correct information could not be acquired. For example, a Contact in SFDC may not have a valid email due to an old mailing list, alias, etc.
| Zendesk | SFCD |
|---|---|
| Zendesk User ID | SFDC ID |
| Price plan | |
| User Fields | Resources |
| Treasure Data Account ID |
In order to unify these data identities, we need master data, which is stored in our service database (MySQL).
| Zendesk | MySQL | SFCD |
|---|---|---|
| Zendesk User ID | Treasure Data Account ID | SFDC ID |
| User ID | Price plan | |
| User Fields | Resources | |
| Treasure Data Account ID |
But, the difficulty comes in how we can load and unify data from multiple data sources.
Data unification solutions and resolutions
We can resolve this data unification issue by using Treasure Data. Additionally, the Treasure Data Service uses Treasure Data to manage log analytics to store all service logs in Treasure Data. So, we can enrich a customer’s information anywhere with their history of service activity and contract and customer support activity and more.
Data loading from all data sources
Quite conveniently, Treasure Data has several connectors to pull data from several data sources easily. You can simply use the connectors by following these docs:
- Data Connector for Zendesk https://docs.treasuredata.com/display/public/INT/Zendesk+Import+Integration
- Data Connector for SFDC https://docs.treasuredata.com/display/INT/Salesforce+Integrations
- Data Connector for MySQL https://docs.treasuredata.com/display/INT/MySQL+Import+Integration
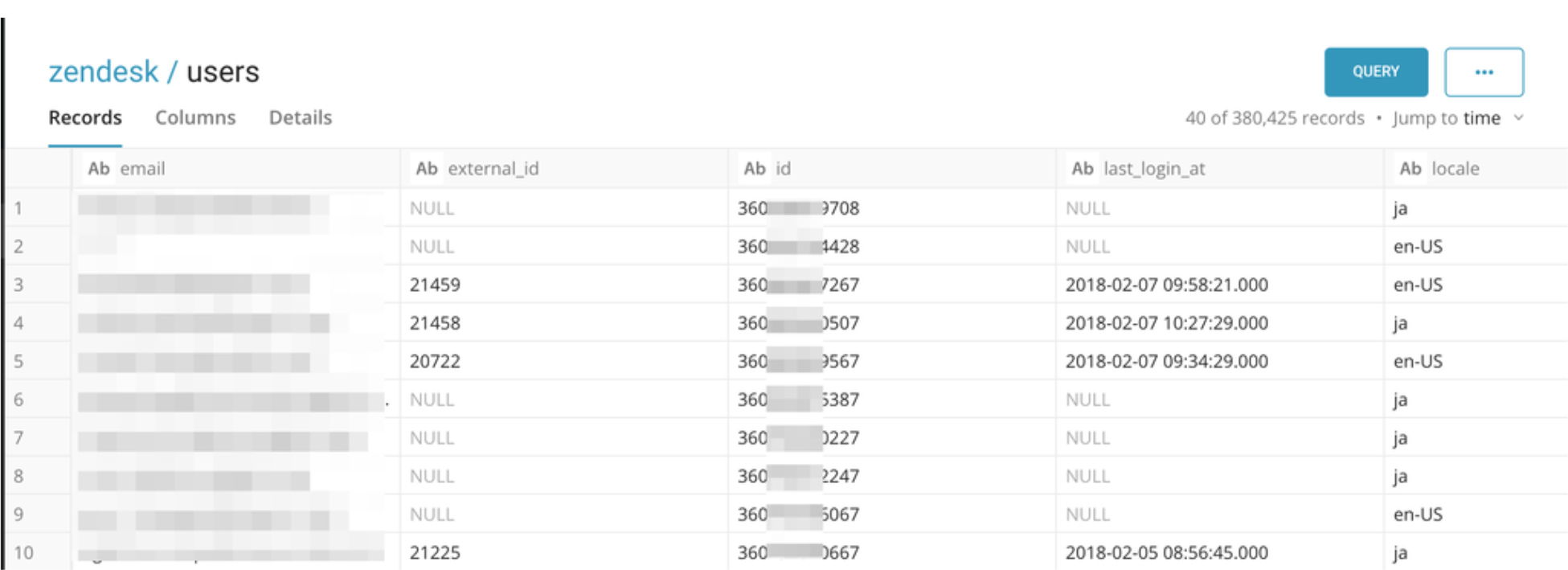
You’ll see the data on Treasure Data as the following:
– Zendesk User
Alternative way: Data loading with Embulk
If you are not our customer (unfortunately), you might feel this article is not helpful. It’s not true.
We love open source, and we love to help people who need to do data engineering in the world. In this case, we recommend Embulk (http://www.embulk.org/docs/), which is an open-source bulk data loader that helps data transfer between various databases, storages, file formats, and cloud services. Our Data Connector is also based on Embulk. And, a lot of connectors are the same source code as open source plugin.
You’ll get almost the same result using Embulk with the following plugins:
- embulk-input-zendesk https://github.com/treasure-data/embulk-input-zendesk
- embulk-input-mysql https://github.com/embulk/embulk-input-jdbc/tree/master/embulk-input-mysql
- embulk-input-sfdc https://github.com/embulk/embulk-input-jdbc/tree/master/embulk-input-mysql
Enrich user fields in Zendesk
Now, you have all your data from multiple data sources in the Treasure Data platform.
Next, I’d like to push these data to User Fields in Zendesk. Unfortunately, for now, we don’t support a connector to export data from Treasure Data to Zendesk User Fields.
As I mentioned, Embulk supports a pluggable architecture. That means it’s easy to develop a plugin for integration to Zendesk User Fields. So, I have developed the following plugin.
- https://github.com/toru-takahashi/embulk-output-zendesk_users
embulk-output-zendesk_users enables to update user_fileds in Zendesk by Zendesk User ID.
With the following plugin, you can pull data from Treasure Data, and push it to Zendesk User Fields by using Embulk. - https://github.com/muga/embulk-input-td
The configuration can be like this:
Before Embulk is executed, you need to define User Fields in Zendesk.
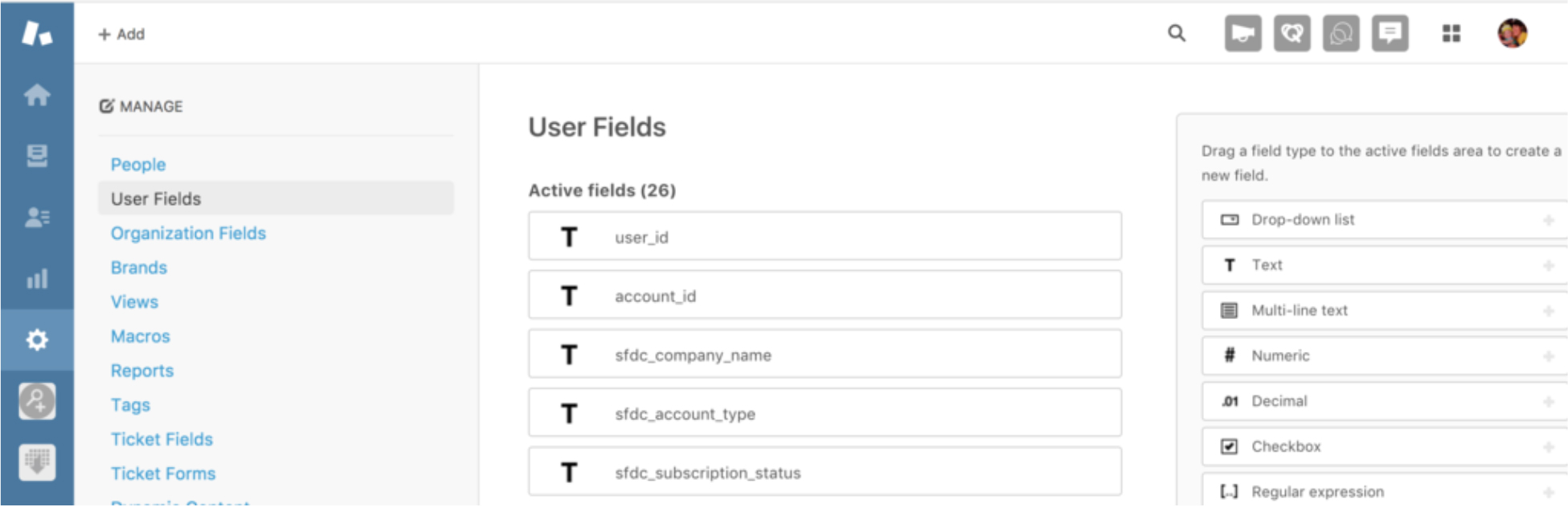
And then, you can update the defined user field by Embulk.
Now you can get any information from SFDC and etc… into Zendesk User Fields.
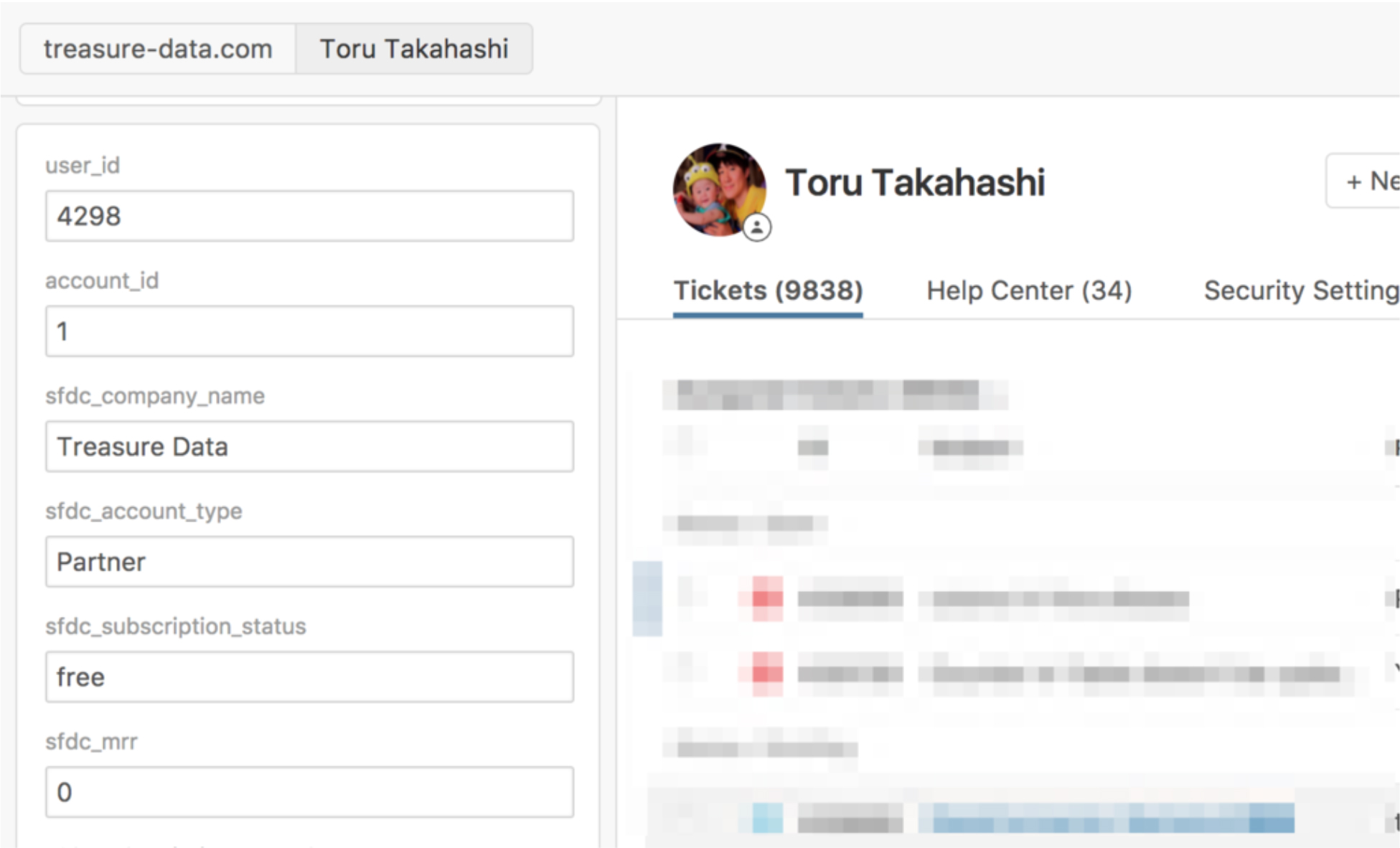
Finally, you can do the following conditions with Zendesk User Fields in Zendesk Trigger!
Build a KPI dashboard on Chartio
Through the above processes, you already have support ticket information from Zendesk.
Next, Treasure Data provides connectivity to BI tools. So, we also use Treasure Data and Chartio for our data analytics platform with customer support Information. For now, we can do information sharing more easily without any special work.
The following graphs show examples of our dashboard in Chartio.
This is a support activity dashboard per quarter for the support team.
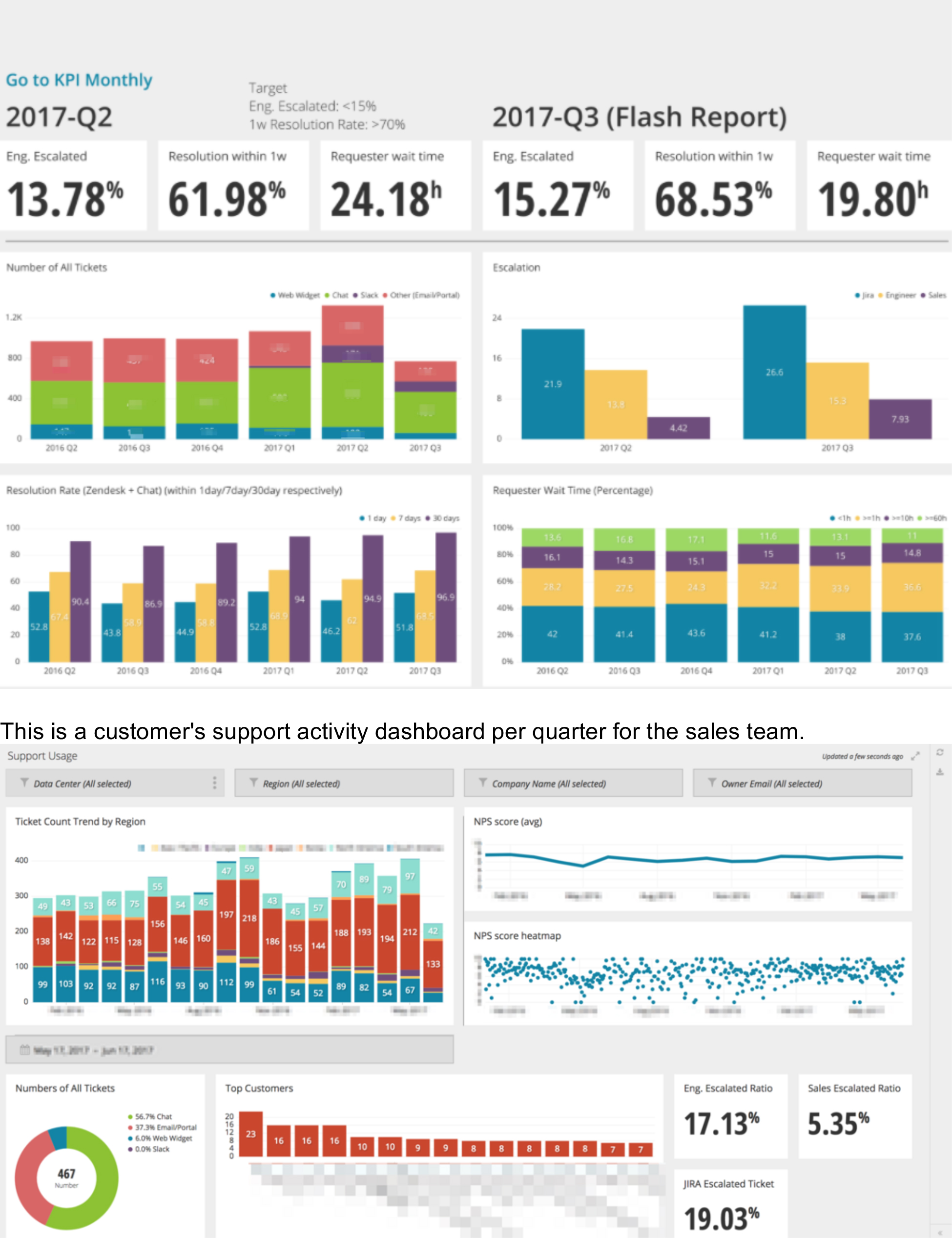
We can build these dashboards easily because all related data is stored in Treasure Data.
Conclusion
In this blog post, I introduced how the Treasure Data support team improves our internal analytics and tools. In order to integrate with several services, we use Treasure Data as the complete underlying data unification platform.
For an enterprise SaaS company, support is an important factor for growth. Having support seamlessly data-driven for our customers is critical. I hope his blog post helps you achieve similar results.
BTW, we’re a growing global team. If you’re interested in joining our support team, please check this page!
https://jobs.lever.co/treasure-data/833b2423-93df-4136-9a21-7a8cf65ca02a.