Surprising Results from a Hackathon
Surprising Results from a Hackathon
Surprising Results from a Hackathon
Here at Treasure Data, our front end development team is fully remote, based in both the US and UK. This arrangement works out great and precludes the ad hoc, in person conversation where the remote employee misses out.
Once a year the team gets together in our Mountain View headquarters for two weeks, during which we try to do a variety of team activities and product discussions while hanging out together. One of the team activities we usually have is a two-day hackathon where you can choose to work on anything Treasure Data-related that you think would be cool – a sort of, “Go forth and hack together a prototype of anything you can think of with our products.”
This is a story of how a Service Worker/Fetch Component project showed us what a super fast response from API could do to improve/accelerate our web application. Read on to learn how.
After an initial discussion on projects and ideas, many cool mini-projects have emerged. Among those, one stood out for me: experimenting with a service worker to act as cache layer for our API data. A service worker is a fairly new browser way to enrich the user experience and offline capabilities by running a javascript script in a separate thread which cannot interact with the DOM directly or share memory with the main thread but can intercept low level calls and communicate using postMessage APIs. With a service worker, it’s possible to gain an impressive amount of access to the browser calls. Specifically, we really wanted to dig into the fetch internals to create a cache.
Caching endpoint responses could provide response times below 10ms, which will help to improve the perceived loading times of our web application. I immediately jumped head first into the project, joining forces with another front end engineer to investigate which kind of improvements we could bring to the table.
Defining the scope for a two-day hack
We started with an idea of what the scope of the project should be for a two-day hackathon project:
- We’d cache only GET method requests
- Our API results are highly dynamic therefore we need to implement a mechanism of updating the cache to the latest data every time a fetch request is done
- We’d need to integrate the above into our current web console application (written in React with a heavy Redux usage) in at least a couple of pages as a test
Architecture
Once we defined the scope, my partner and I sat down with a couple of markers and a whiteboard and started jotting down ideas on which parts we needed and how they should roughly work and integrate.We decided to split the project into two parts: (1) the service worker itself and (2) the UI integration/usage of the service worker.
Our service worker would intercept API requests made via fetch, and check if the data had been requested previously. If it had, it would return the cached version immediately and execute the original request. When responses returned from the API, we would update the cache with the new response, and notify the UI that we had new data for a specific endpoint.The UI would execute a standard fetch request, and start listening for updates for a specific endpoint. Upon notification of such updates, it would fetch the updates and notify all of its children to re-render.
Drawing and discussing a basic architecture helped us figure out all of the moving parts beforehand.
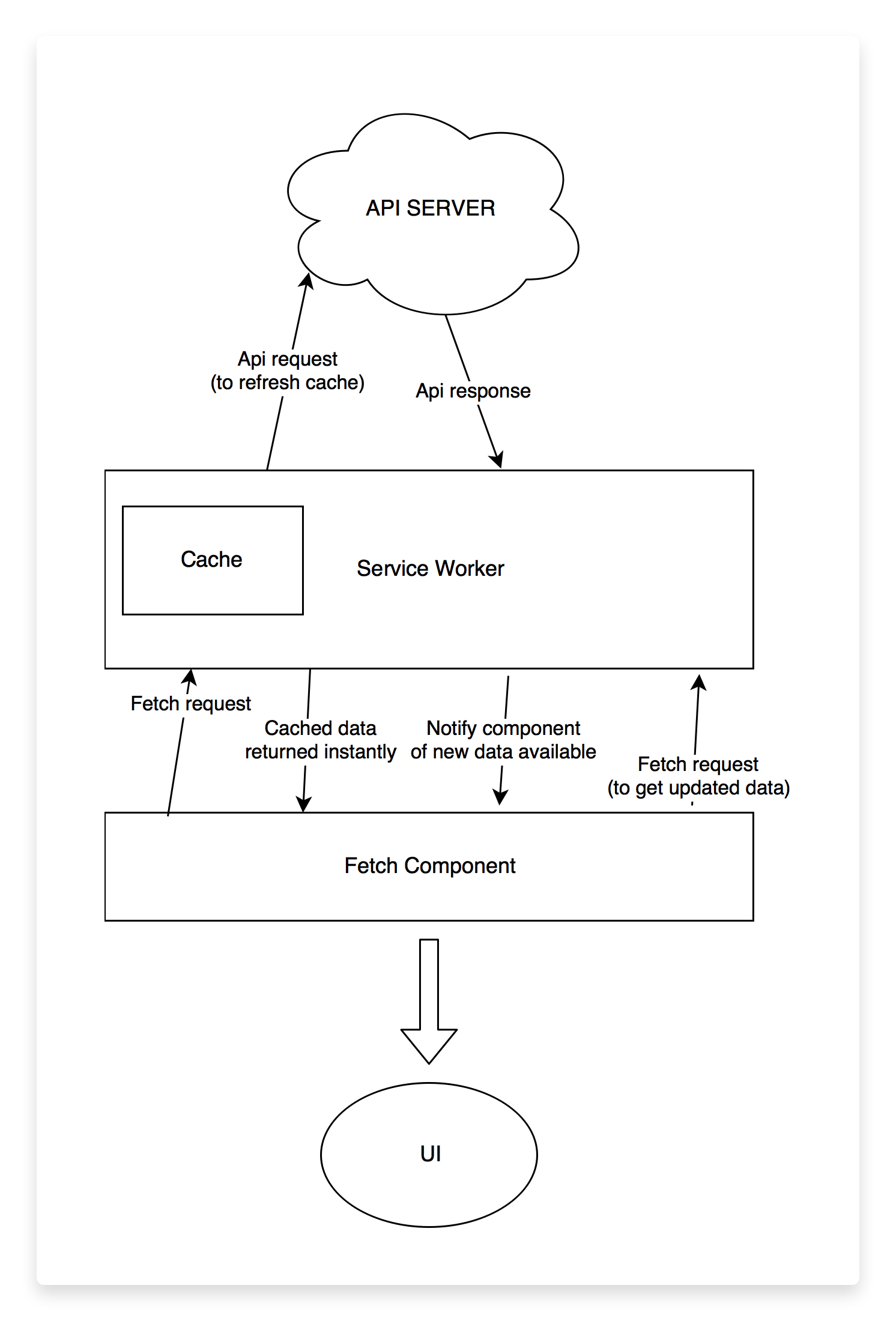
Given that, we quite conveniently determined there were two moving parts in play and two of us, so we decided to split the workload between us. I would take care of the service worker part and my partner would handle the UI side.
The Service Worker
The first step for the service worker was to write a super simple worker that would just act as a caching layer. Turns out this was fairly trivial, and after a few Google searches, reading some MDN pages and a good hour or two of coding, that part was done.
After implementing a simple cache layer, there are two main problems to solve in order to achieve the data refresh, the flow should be something like:
- If we have cache for that request, respond immediately with the cached version, and refresh the cache for that request in the background
- Let the application know that we have new data available for a specific url
To tackle the first point, the cache implementation layer could be achieved reasonably simply by using the service worker cache spec.
For the second, the solution wasn’t super clean. Service workers can send messages to the web application, but those messages can’t share memory. This meant we couldn’t share the responses from the updated fetch. Our approach to resolve this was to create a listener app-side that implements a subscription model to handle notifications.
The Fetch Component
The first step for the UI was to create a Fetch component with render props (similar to the one Ryan Florence explained here). Render props are a specific React use case where a property, instead of being a node or a list of nodes, is a function which returns a node or a list of nodes and is called as a part of the component’s render function, allowing composition of the children components with internal, encapsulated state inside the component. For this case, we’d want the render prop to be the child of the Fetch component.
With render props we can pass the current fetch status and result down to the UI components. This solves the problem of updating the UI when fresh data comes in and allows us to pass down callbacks in a typical parent -> children react-y fashion. The API surface of such component looks similar to this:
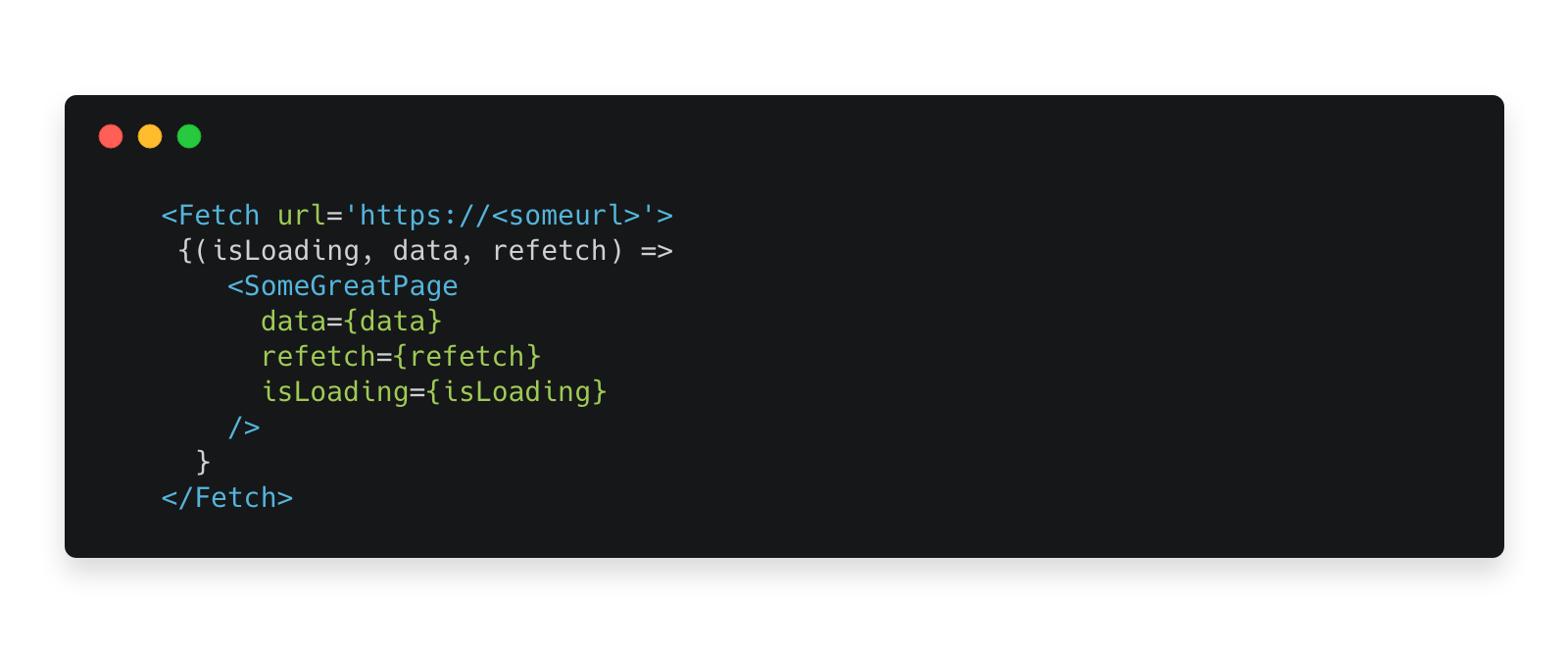
Internally, the fetch component works in a very similar way to a subscription model based fetch.
The subscription model is necessary because we need to update the cache for each endpoint for every request (in order not to display stale data for too long).
When the service worker notifies us of new data, to refresh the internal state, and as result have up-to-date data, this component re-executes the same fetch. This operation however needs to communicate to the service worker not to execute another fetch to API as result of this, otherwise we’d create an infinite loop of fetch -> refresh -> fetch -> repeat. We decided that the simplest way to achieve this was to add a header to let the service worker know we only wanted the cached version.
Using React setState, each time new data is available, it will trigger a re-render of any children components, thus updating the new.
Follow-up
At this point we were pretty satisfied with how far we had come, but one question remained: what if the user’s browser doesn’t support service workers at all? While the vast majority of our users use service-worker-compliant browsers, we wanted to make sure we wouldn’t be breaking the experience for the few users still on older browsers. ? Service workers are not polyfillable at this stage, but we implemented a very similar behavior to be run in the browser’s main thread (we ended up re-using 80% of the code for the service worker). The cache, instead of the service worker cache, is a simple map of request urls as keys and responses as values. One drawback of this implementation was that the cache would not persist through refreshes (the same way the service worker cache would), but it still offers performance boosts since no reloads are necessary while page switching due to our use of client side routing.
Overall results reduced time to render by half!
Once all the pieces were put together, we were surprised at the results.With a faster apparent response time from the cache, users perceive the webapp itself as faster. We were very impressed with the results with the service worker in the pages where we integrated it. In some attempts we slashed the time to first render by half, even though it meant displaying possibly stale data for a fraction of a second, the usability feedback was great.
Takeaways
This Service Worker/Fetch Component project showed us what a super fast response from API could do to our web application, and how much cleaner some parts of our code could be like if we used Fetch Components and delegate our internal caching to a service worker. This made us realize that we still have so much room for performance improvement in our front end app.
Both the service worker and the fetch components independently provide really good improvements that we can adopt. As a team, we’ve decided that both parts of the project are worth revisiting but further prototyping is definitely necessary before making an adoption decision.