How to Get More Clicks for Digital Advertising: Step by Step Guide to Optimizing CTRs with Real-time Data + Machine Learning
How to Get More Clicks for Digital Advertising: Step by Step Guide to Optimizing CTRs with Real-time Data + Machine Learning
How to Get More Clicks for Digital Advertising: Step by Step Guide to Optimizing CTRs with Real-time Data + Machine Learning
In the digital advertising space, optimizing the CTR (Click Through Rate) is one of the major challenges to increasing the performance of the advertising networks. Often times, machine learning algorithms are used to optimize what ads are relevant to the incoming visitors by learning from the historical impression and click logs. However, collecting and running machine learning algorithms in real-time often requires specialized (and expensive!) hardware, software, and engineering resources. But it doesn’t have to!
In this post, I introduce a step-by-step guide for building a real-time CTR optimization system in just a few hours using Treasure Data. This example is end-to-end, meaning it uses one example from the real-time data collection to the learning algorithms. And going beyond that, we’ll describe how to score the incoming new impression requests with the models.
Understanding the Architecture
The diagram below depicts the entire CTR optimization system architecture. It’s easy to implement in a few simple steps: 1) Collect the data in real-time, 2) Prepare data 3) Run the machine learning algorithm 4) Use the model. All steps are learning to continuously revise the model with incoming data.
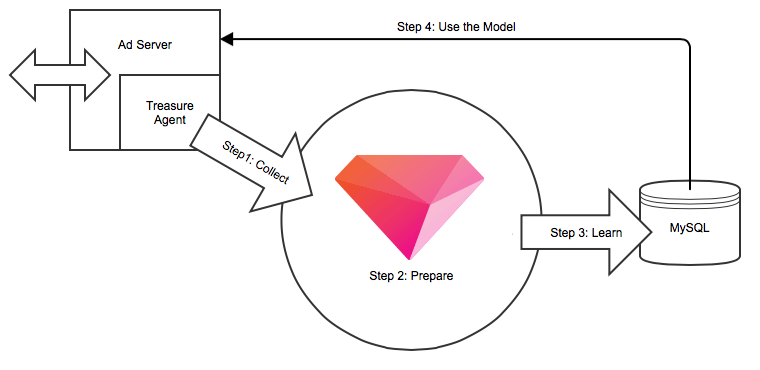
Are you ready to get started? Here are the steps. If you’re not signed up for Treasure Data yet, it’s easy, free and fast to get an account now.
Step 1: Setup Real-time Data Collection
Treasure Agent is a streaming data collection agent built by Treasure Data. It is specifically designed to collect time-series event data, such as impression or click logs. One of our customers has more than 3000+ servers running Treasure Agent, and is continuously collecting the data and streaming it into the cloud. The installation of Treasure Agent is really easy. Please download the appropriate package (.deb, rpm, deb), and install it using the documentation.
# MacOS X 10.8,10.9 (documentation) $ open 'http://packages.treasuredata.com/2/macosx/td-agent-2.0.3-0.dmg' # RHEL/CentOS 5,6 (documentation) $ curl -L http://toolbelt.treasuredata.com/sh/install-redhat.sh | sh # Ubuntu 10.04,12.04 (documentation) # 10.04 Lucid $ curl -L http://toolbelt.treasuredata.com/sh/install-ubuntu-lucid.sh | sh # 12.04 Precise $ curl -L http://toolbelt.treasuredata.com/sh/install-ubuntu-precise.sh | sh
We are assuming you are already signed up with Treasure Data (if you aren’t, it’s easy and free to get started). Please retrieve the API key from here, and put the key into /etc/td-agent/td-agent.conf like below.
# Input from Logging Libraries <source> type forward port 24224 </source> # Treasure Data Output <match td.*.*> type tdlog apikey YOUR_API_KEY auto_create_table buffer_type file buffer_path /var/log/td-agent/buffer/td use_ssl true </match>
Next, let’s post the impression and click events from the application. The example below is using Ruby, but Treasure Agent also supports most of the common programming languages. TD.event.post() function will post the event to the local Treasure Agent. Treasure Agent buffers the logs under /var/log/td-agent/buffer/td, and periodically uploads to the cloud or every 5 minutes by default. Please visit the database page to confirm that the data gets uploaded correctly.
# Initialize
require 'td'
TreasureData::Logger.open_agent('td.sampledb', :host=>'localhost', :port=>24224)
TD.event.post('impressions', {
:imp_id=>'312ffdsa9fdsa09fdsafads',
:user_id=>10000,
:publisher_id=>12345,
:advertiser_id=>7691,
:campaign_id=>456,
:creative_id=>9134,
:ad_id=>789,
:gender=>0,
:generation=>10,
:area=>40})
TD.event.post('clicks', {
:imp_id=>'312ffdsa9fdsa09fdsafads',
:click_id=>'ABJKJFDSKA312FSA321321ACQE'})
Step 2: Prepare Data Set
Next, let’s prepare the data set for the machine learning algorithm. Treasure Data bundles Hive-based Machine Learning into a library called Hivemall. Hivemall implements machine learning algorithms as a collection of Hive UDFs, so it’s really easy to use. If you’re familiar with SQL, you already know how to use it. Before running the actual learning algorithm, we need to prepare the impressions and click log data so Hivemall can process them.
Here’s an example of Hive query joining impressions and clicks across the table. From Web UI, you can write the query result into other table called ‘joined_table’ by using the Result Output feature.
SELECT
i.time as time,
mhash(i.imp_id) AS row_id,
CAST(IF(click_id != "", 1.0, 0.0) AS float) AS label,
array(
mhash(concat("1:", i.user_id)),
mhash(concat("2:", i.ad_id)),
mhash(concat("3:", i.publisher_id)),
mhash(concat("4:", i.advertiser_id)),
mhash(concat("5:", i.campaign_id)),
mhash(concat("6:", i.creative_id)),
mhash(concat("7:", i.gender)),
mhash(concat("8:", i.generation)),
mhash(concat("9:", i.area)),
-1
) AS features
FROM
impressions i
LEFT OUTER JOIN
clicks c
ON
(i.imp_id = c.imp_id)
The query result contains two key fields: label and features. The label is 1.0 if the impression was clicked and is 0.0 if it wasn’t clicked. Features are the collection of elements, which are associated with the particular impressions. The algorithms will learn what features will contribute to the click at the later stage. You can add whatever features you want here.
We’re also using mhash() function provided by Hivemall. mhash() is an implementation of Murmurhash3 hashing function. Here we use mhash() to decrease the size of features, so that we can represent features as array<int> rather than array<string>. This will greatly improve the machine learning algorithm performance, while maintaining the precision.
Treasure Data’s Scheduled jobs feature allows you to execute this data preparation job periodically, so that the ‘joined_table’ is constantly updated with the fresh data.
Step 3: Run the Machine Learning Algorithm
Now we collect and prepare the data. Let’s run the learning algorithm called Logistic Regression. This is the easiest step because Hivemall hides a lot of the complexity. Run the following SQL below to build the model.
SELECT CAST(feature as int) as feature, CAST(AVG(weight) as float) as weight FROM ( SELECT logress(features, label,'-total_steps 5') as (feature, weight) FROM joined_table ) t GROUP BY feature
The query result contains two fields: feature and weight. The result represents what ‘feature’ has how much of the ‘weight’ to contribute to the clicks. By using our Result Output to MySQL feature, you can easily store the calculated model to a MySQL database or other database systems supported by Treasure Data. You can schedule this query to run periodically which will keep updating the model.
Step 4: Choose the Best Ad for Incoming Requests
Finally let’s optimize the newly incoming impressions. Here’s the code snippet to choose the best performing ads for the incoming request. We’re using the same hash function of Hivemall’s mhash() function here to map the character based feature name into integer. Also we’re reading the model stored within MySQL. Finally we’re iterating on the ads that we have, scoring, and then picking the ads with the highest score.
require 'murmurhash3'
def mhash(str)
# To be compatible with Hivemall's mhash() function.
# @see http://bit.ly/1xKAfqN
r = (MurmurHash3::V32.murmur3_32_str_hash(str, 0x9747b28c)) & (16777216 - 1)
(r < 0) ? r + 16777216 : r
end
$model = read_model_from_mysql()
def scoring(i, a)
features = [
"1:#{i.user_id}",
"2:#{a.ad_id}",
"3:#{i.publisher_id}",
"4:#{a.advertiser_id}",
"5:#{a.campaign_id}",
"6:#{a.creative_id}",
"7:#{i.user.gender}",
"8:#{i.user.generation}",
"9:#{i.user.area}",
]
features.inject(0) { |sum, f| sum += $model[mhash(f)] || 0 }
end
impression = ...
ads = ...
best_performing_ad = ads.map{|ad| [scoring(impression, ad), ad]}.sort.last[1]
Conclusion
In this blog article, we showed an example of how to optimize digital advertising performance by using real-time data and the machine learning algorithm. This example uses Treasure Data, but the concept itself can be generally applied. Treasure Data allows you to focus on improving your business performance, while forgetting entirely about severs, infrastructures, configurations, etc. Let Treasure Data manage that part for you.
We have a number of talented engineers maintaining and improving the Treasure Data Service. Ryu Kobayashi, one of our backend software engineers, has been instrumental in integrating Hivemall into Treasure Data.