Data loading into Amazon Redshift simplified: The Podcast, part 2
Data loading into Amazon Redshift simplified: The Podcast, part 2
Data loading into Amazon Redshift simplified: The Podcast, part 2
You can hear the whole podcast at this link.
As we saw in Part 1 of this series, there are at least two sides to the development of any software feature; one is the perspective of the business person who requires the feature and then other is that of the developer who must create and maintain it.
While software requirements state in plain language what the thing is expected to do; the devil is typically in the details; in other words, what looks simple on the surface can be incredibly complex under the hood.
However, understanding these details is useful, especially if you or your team are ever tasked with the non-trivial task of moving data from one type and location of a data store to another.
Treasure Data supports result output into Amazon Redshift. This means you can use Treasure Data as a funnel to get multi-structured data from a myriad of sources into Redshift’s MPP schema with the press of a button, saving you time (otherwise spent dealing with ETLs) and money (otherwise spent running queries directly on Redshift).
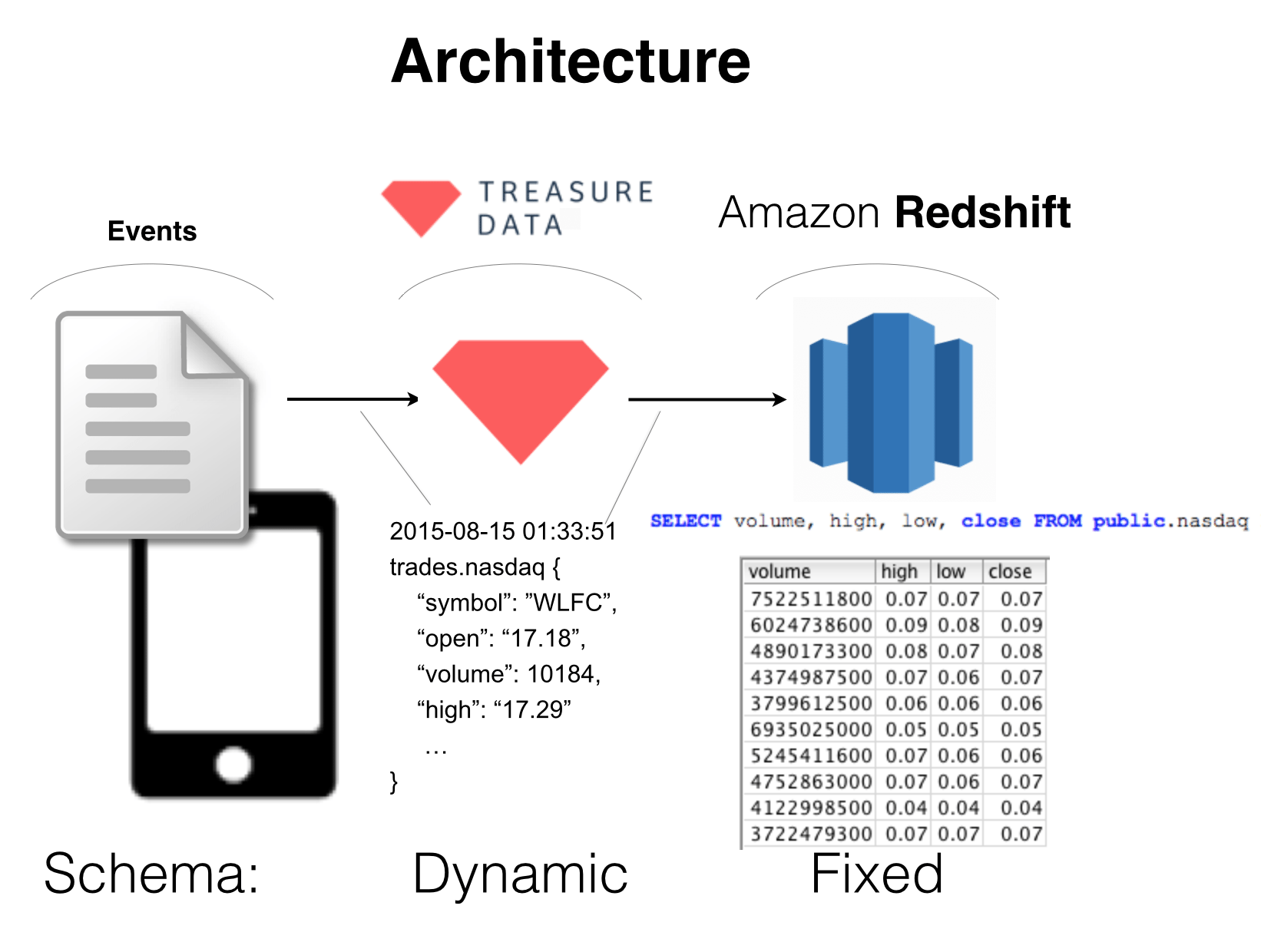
But building the feature to make the conversion wasn’t simple. In some selected extracts from our interview (starting from ~12:48 in the audio), the architect and creator of the feature, Sadayuki Furuhashi, explains.
Treasure Data: How did Amazon Redshift Result output get on your desk?
Sadayuki Furuhashi: So, one customer wanted to move some data. Especially old data. Away from Redshift, and toward Treasure Data. They had a large dataset on Redshift, but because of its cost, they wanted to move all data from data on Redshift. They didn’t have to keep all data on Redshift. Their visualization uses only recent data, but they wanted to keep the old data queryable. There’s one use case where Treasure Data plus Redshift works very well. But because they already have visualization working with Redshift, they want to output query result into Redshift.
TD: I wanted to ask you some specific questions about the implementation itself. You made a statement that “RS result is the most complex result worker to make reliable and user friendly.” Can you offer some insight into that?
SF: Sure. Users prefer semi-structured data first, because the world consists of semi-structured data. And we use Hadoop or Presto to calculate that data. On the other hand, on Redshift, there is structured data only. So ETL is called to load structured data into RS or RDBMS, but these days, because we can store semi-structured data, we can load first, then translate into structured world. So Extract, Load, then Transform and push to structured world. And this RS result is the interface between semi-structured world and structured world. So this conversion is actually very complicated.
TD: What were some of the painful parts of that implementation that you ran into?
Sadayuki Furuhashi explains Fluentd at Rackspace.
SF: So, on Redshift, there are specific types, for example varchar, which accepts up to 255 characters, BigInt, and integer (a lot of types); these are predefined. On the other hand, cause this is on Treasure Data’s side, because it is semi-structured data, the type is more loosely defined.
There are a lot of differences [sic] Same structured data does not always have strict validation. It can have too large integers; it can have no values. On the other hand, Redshift does not accept these. So this conversion layer needs to normalize invalid data so that Redshift can accept it.
In many cases it almost doesn’t happen where old data is invalid. In new data, some data is always invalid. But we don’t want to reject all data in that case. We want to roll most data and then find the broken record and then do something later on that small amount of data.
TD: I see. So how would you describe some of the architecture concepts behind Amazon Technologies that you needed to master before you could implement the feature?
SF: Yes. So there are two things. One is the type conversion. The other is performance.
What is virtual type in Redshift? By default virtual type is actually only 255 characters. But in many cases a lot of characters do not fit in the size. How can we overcome that limitation? I needed to learn the specification for us to think of that solution. That is one thing.
The other thing is performance. If we import records to Redshift one by one, it’s very slow. Install one record, install the next record; too slow.
TD: How did you work around that?
SF: the Redshift Output creates a csv file first. Then uploads it to S3. Then it runs an SQL command called COPY on Redshift. Then bulk loads that data into Redshift. This COPY command runs faster if the S3 region is in the same region with the Redshift instance. So Redshift first creates a system file. Then finds the nearest S3 bucket to the target Redshift cluster. So, for example, if Redshift is in, for example, Tokyo – Redshift finds an S3 bucket in Tokyo, then uploads this system file. This copy runs much faster than in a situation [sic] where the bucket is in, say, New York.
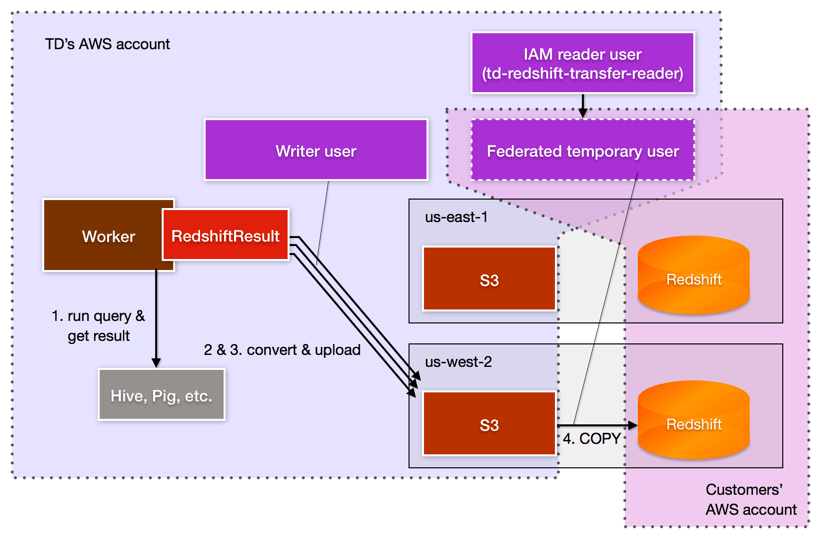
We asked many more questions from Sada. For more insights into the architecture, design and implementation of Treasure Data’s Amazon Redshift Result Output, listen to the podcast here: https://soundcloud.com/johnhammink/redshift-podcast-interview-with-sadayuki-furuhashi-and-prakhar-agarwal