AWS, SFDC and Marketo Data Connectors Released, Data Tanks in Beta for Broader BI Connectivity
AWS, SFDC and Marketo Data Connectors Released, Data Tanks in Beta for Broader BI Connectivity
AWS, SFDC and Marketo Data Connectors Released, Data Tanks in Beta for Broader BI Connectivity
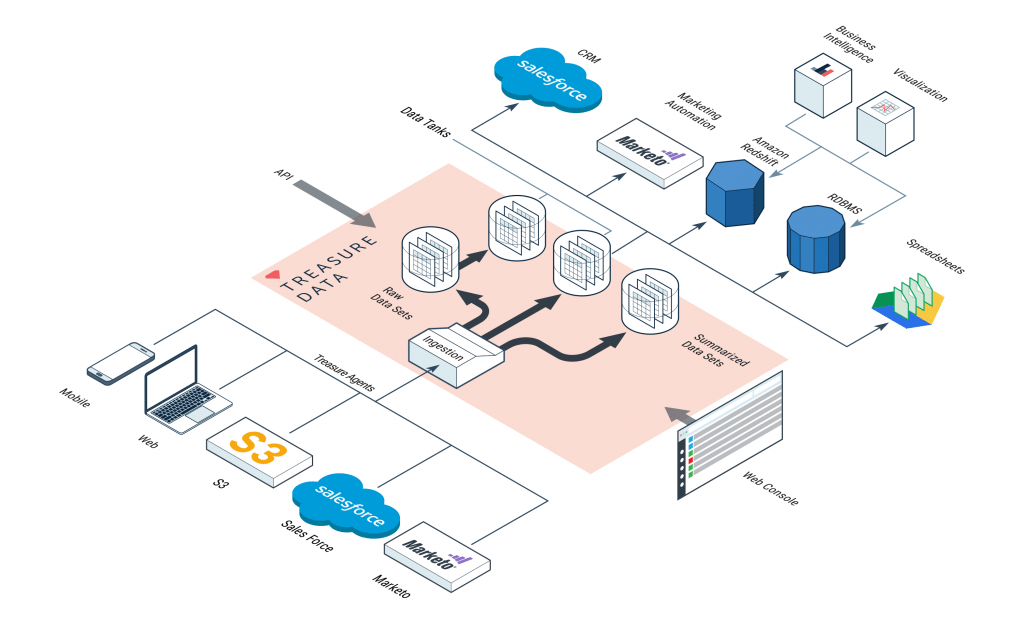
This year’s AWS re:Invent brings many new announcements and features from Treasure Data. Specifically, we released AWS Data Connectors (S3 and Redshift) and SaaS Data Connectors (Marketo and Salesforce) for general availability and Data Tanks for private beta. Also, the new workflow management feature as well as the new API and web console are slated to be available in Q1 2016. We are excited to see these new features used to help our customers simplify analytics and data management.
And so, without further ado…
AWS Data Connectors (S3 and Redshift)
Launched as beta back in June, our data connector for S3 lets you pull data from S3 buckets (either .tsv or .csv files) into Treasure Data, where you can query them and export them to a variety of data destinations.
With our S3 Data Connector – as with any of our input connectors – the steps for importing data are simple, assuming you have the latest Treasure Data Toolbelt installed:
-
- Create a seed.yml configuration file:
config: in: type: s3 access_key_id: XXXXXXXXXX secret_access_key: YYYYYYYYYY bucket: sample_bucket path_prefix: path/to/source_file.csv #or .tsv out: mode: append
- Create a seed.yml configuration file:
-
- Guess the fields in the data to be imported:
$ td connector:guess seed.yml -o load.yml
- Guess the fields in the data to be imported:
-
- Create the database and table on Treasure Data to where you’ll import your S3 (or external source) data:
$ td database:create td_sample_db
$ td table:create td_sample_db td_sample_table
- Create the database and table on Treasure Data to where you’ll import your S3 (or external source) data:
-
- Load the data:
$ td connector:issue load.yml –database td_sample_db –table td_sample_table –time-column created_at
- Load the data:
Your mileage may vary; for a specific example of a real world use-case using the S3 connector to import data into Treasure Data, check out this blog post on getting Landsat data from S3, or our documentation online.
With our Amazon Redshift Data Connector, you can export Treasure Data query results into Redshift to get the best of both worlds: collect, store and pre-process messy event data in Treasure Data, output massive but tidy data in Redshift for ad hoc analysis and further reporting.
By adding one more command to the above, you can export result output into Amazon Redshift, thus creating a complete, simple data pipeline from Amazon S3 to Redshift (but in fewer steps). In this example, we use our Presto engine:
$ td query –result “redshift://test:@/path/to/test_table?ssl=true&method=copy” -d td_sample_db “select * from td_sample_table” –type presto –wait
You can also export results from any Treasure Data query back into S3.
SFDC and Marketo Connectors
If you’ve ever wanted to get data out of disparate data silos, for example landing page user behavior events and Salesforce CRM data, then our Salesforce Data Connector and Marketo Data Connectors might be just the ticket.
All of our input data connectors work with the same steps as above. In the case of Salesforce Data Connector, the seed.yml looks as follows:
config:
in:
type: sfdc
username: your_salesforce_username
password: your_salesforce_password
client_id: your_salesforce_client_id
client_secret: your_salesforce_client_secret
security_token: your_salesforce_security_token
login_url: https://your_host.salesforce.com/
target: Account
out:
mode: replace
The Marketo Connector requires this seed.yml:
config:
in:
type: marketo/lead
endpoint: https://your_marketo_endpoint
wsdl: https://your_marketo_WDSL
user_id: your_marketo_user_id
encryption_key: your_encryption_key
from_datetime: "2014-01-01"
out:
mode:replace
It’s worth noting that our Salesforce Data Connector is bi-directional: Once you have munged, filtered, joined and summarized data inside Treasure Data, your query results can be pushed right back to Salesforce.
Data Tanks (Private Beta)
Data Tanks were born out of customer feedback. As our customers began to build larger parts of their analytics pipeline, they noticed that Treasure Data was missing the last mile of it: the data store to hold summarized results so that they can be accessed from various Business Intelligence tools. We have long supported Tableau Server for Tableau enthusiasts, but up until now, our support for many other BI tools required our customers to run their own data marts.
This is no longer the case with Data Tanks.
Data Tanks is a PostgreSQL-based, fully managed data mart as a service. Because it is based on PostgreSQL, all standard BI tools are supported out of the box. Data Tanks is currently in private beta and offered to select existing customers (Existing as well as new customers, please ask us about it!).