Redshift is 400x Bigger than MySQL Yet MySQL is More Popular
Redshift is 400x Bigger than MySQL Yet MySQL is More Popular
Redshift is 400x Bigger than MySQL Yet MySQL is More Popular
The Amazon Redshift COPY Command Guide is now available!
There are good reasons for the hype around Amazon Redshift. Redshift is blazing fast and not that much more expensive than MySQL or PostgreSQL, the traditional mainstay of data engineers. But is Amazon Redshift really becoming predominant in the world of analytic databases, taking over its smaller siblings (like MySQL) as an analytics backend?
It would be glib not to concede that MySQL is designed for online transaction processing (OLTP), and the comparison is apples to oranges. However, for those who have been in the trenches, the story of “exploiting” MySQL as an analytic database must sound all too familiar: With a combination of intelligent schema design and sharding, many data engineering teams have built not-so-enterprise, poor man’s data warehouses atop MySQL and PostgreSQL.
While this solution costs a fraction of a similar solution using Teradata or Oracle, it is far from free: It is expensive to maintain and scale any data infrastructure because of the cost of the people managing it. Enter Redshift. By paying a bit of money to Amazon, Redshift customers can run the same queries faster and with much less maintenance. Is Amazon Redshift therefore a no-brainer?
Our own data paints a more nuanced picture, however. Because Treasure Data’s service fills the data lake/data refinery gap between event data and data warehouses, we can track which structured data stores our customers output data to: MySQL, PostgreSQL, Redshift, or Tableau Server, to name a few. In Treasure Data’s lingo, we’re looking at Result Output.
The most popular Result Output is not Redshift, as one might expect. It’s MySQL, as shown in the graph below:
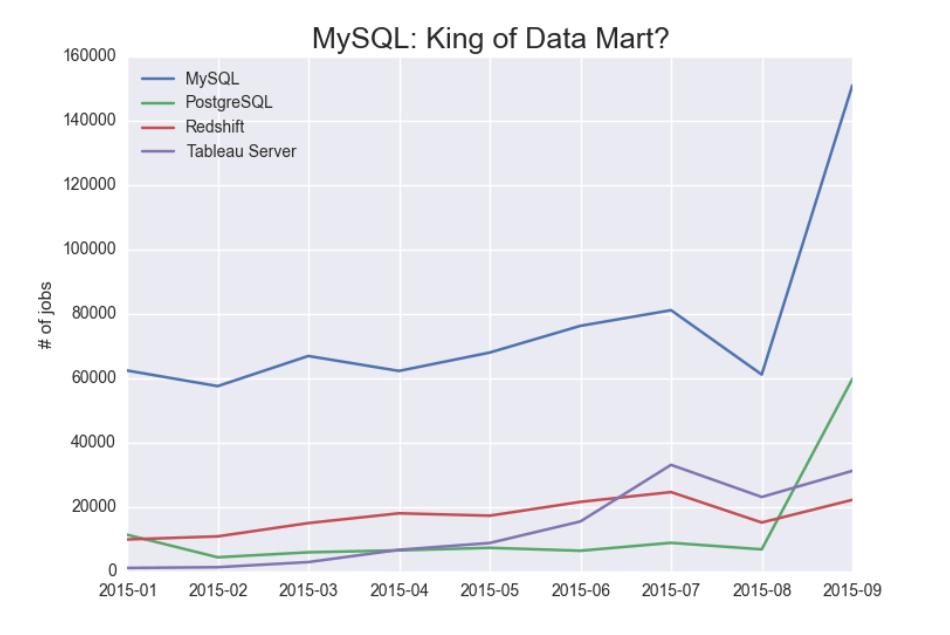
The graph shows the frequency of Treasure Data Result Outputs since January 2015, and MySQL clearly continues to dominate by this measure. One theory for this outcome is that many organizations use MySQL as a data mart: a data store that stores summarized data for quick lookups such as daily active users, weekly bounce rates, monthly revenue, etc. out
On the other hand, loading data into Redshift requires great care. You must ensure that distkey is set properly, the COPY command is run properly, and your tables are vacuumed judiciously to ensure performance. In database parlance, Redshift is read-optimized while MySQL is (comparatively) write-optimized. MySQL can effectively load small volumes of data more frequently. In contrast, Redshift is more efficient at loading large volumes of data less frequently.
Hence, it might be more informative to look at the total output data volume rather than frequency. Indeed, plotting the total output data volume gives us a very different picture, as shown below:
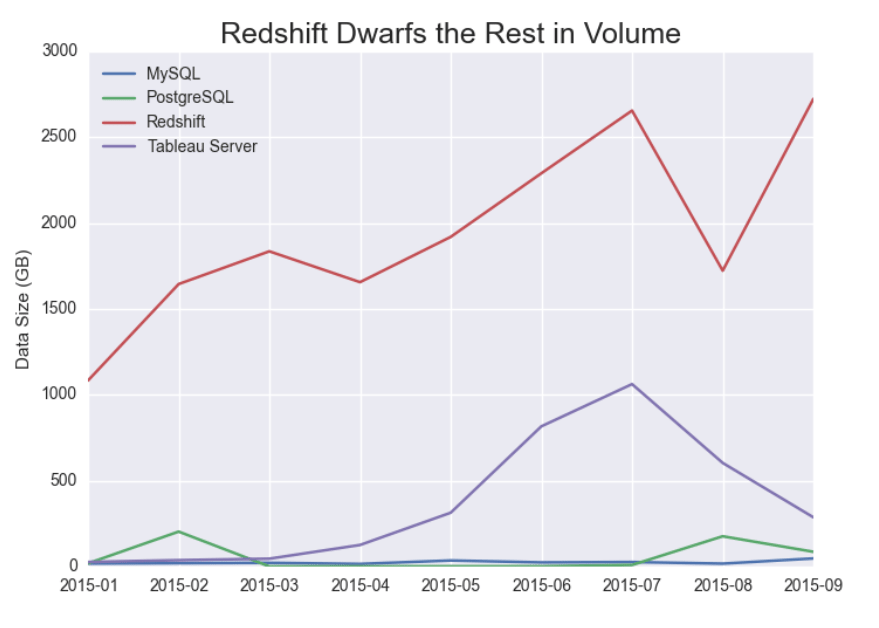
As you can see, Redshift dwarfs the other three in terms of data volume, leading us to believe that Redshift is used less as a data mart and more as a structured counterpart to Treasure Data’s data lake. The comparison with MySQL is indeed staggering. Zooming into September 2015, the Result Output for Redshift is 400 times larger than that for MySQL:
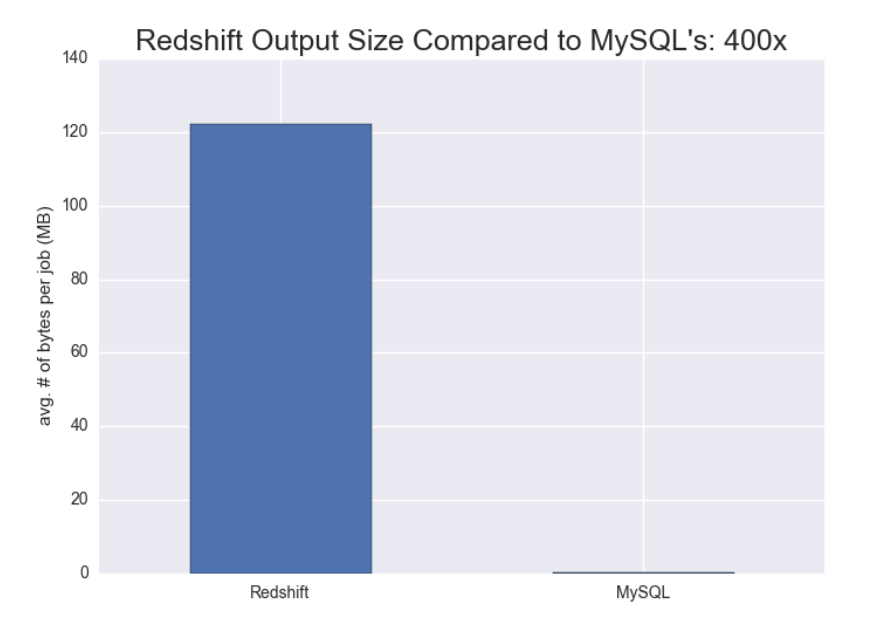
Does this mean we should all migrate from MySQL to Redshift for analytics? The answer really depends on your needs. For example, if you need to update your data frequently without much engineering work and your dataset remains small, MySQL is still a fine choice as an analytics backend, especially if you design schema correctly. However, if you have a large dataset that you want to make available to an army of data analysts for various complex analytical queries, your engineers might prefer Redshift to maintaining a sharded MySQL cluster.
If you are interested in learning more, sign up for our Redshift COPY Command Guide.