Announcing Data Tanks: Faster Reporting and Unlimited Connectivity
Announcing Data Tanks: Faster Reporting and Unlimited Connectivity
Announcing Data Tanks: Faster Reporting and Unlimited Connectivity
Today I’m happy to announce a new addition to Treasure Data’s world-class analytics infrastructure: Data Tanks.
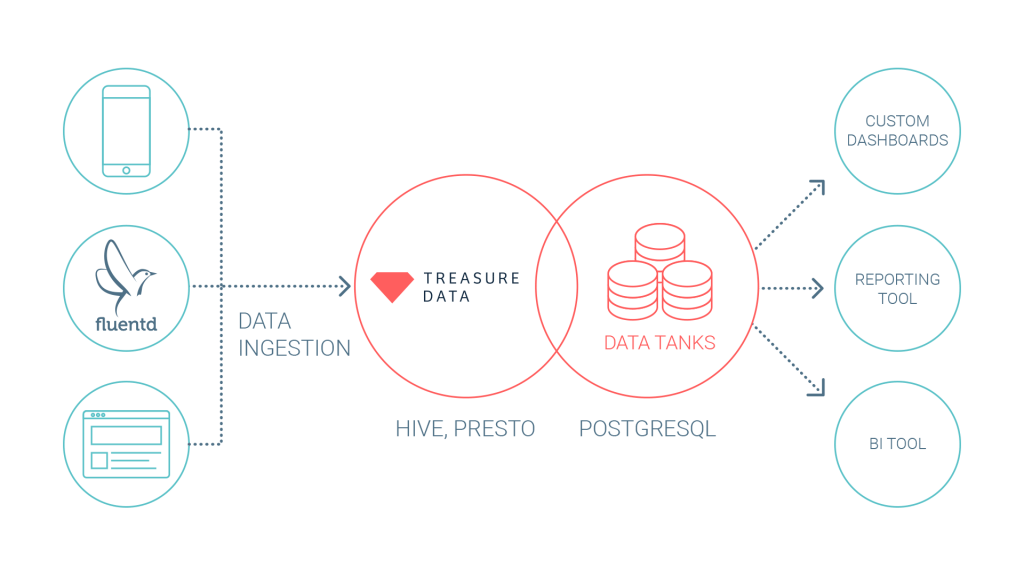
Data Tanks provide easy access to your aggregated metrics through convenient, fully hosted data marts on Treasure Data’s core platform. They can be used to drive a variety of external business intelligence and visualization applications without the hassle of manually hosting and maintaining your own PostgreSQL instances.
Data Tanks were born out of the observation that most of our customers were already using a data mart to drive visualization and business intelligence tools. Many of them asked us to ease the burden of managing that part of their infrastructure as well, and we said “yes”.
What’s Data Tanks?
Data Tanks are PostgreSQL databases that use a columnar store to accelerate analytical queries. They are completely managed by Treasure Data on behalf of our customers. That means that we handle creation, setup, monitoring, management and troubleshooting so our users can just get their job done.
We chose PostgreSQL as the base for Data Tanks for two reasons:
- Due to the massive popularity of this open source project, almost anyone working with modern databases has worked with PostgreSQL and knows how to write queries against it.
- The selection of tools available for this platform is virtually unlimited.
Another excellent feature of PostgreSQL is its ability to use foreign data wrappers, a capability we use to enable Data Tanks to query data from the main Treasure Data event data lake.
We used the open source project cstore_fdw to enable columnar storage and unlock blazing fast query response (up to 50% faster than vanilla PostgreSQL), along with up to 12x better compression reduce storage costs.
Interesting, how do I use this Data Tank then?
Exporting data to a Data Tank is just like using a normal TD result export, and becomes automatically available after your feature activation request is fulfilled (ask us how).
Data Tanks are not intended as the main storage for your transactional data, but as a complement to your analytical workflows on Treasure Data.
Treasure Data can be considered an “event data lake” where disparate event data sources (and a few slow moving dimensions) are aggregated and processed to create more compact and “cleaner” data packages for further processing, analysis or visualization.
Given its architecture, providing highly concurrent interactive access over trillions of data points while retaining schema flexibility is prohibitively expensive. Instead, we’ve implemented Data Tanks in a design pattern sometimes referred as “lakeshore data marts”.
What’s next?
Data Tanks is available on a per-request basis as of today. You can fill out this form to get started.
We’ll be launching quite a few exciting improvements and additions to the Treasure Data platform over the next 6 months. We’ve been working around the clock to completely re-think our user experience, the interoperability of our system with other data tools and the flexibility of our data pipelines.
All of this work will start making its way to our users during 2016 but we’re still looking for more information about what would improve your experience with Treasure Data. If you’re a customer or a past trial user, please let us know your thoughts by going to this link and adding your feature requests.