Mixpanel Doesn’t Like SQL
Mixpanel Doesn’t Like SQL
Mixpanel Doesn’t Like SQL
A couple of weeks ago, Mixpanel released JavaScript Query Language (JQL) as a new way of analyzing event data inside Mixpanel. It’s clear that the Mixpanel team has realized that giving non-clunky access to raw event data empowers their users.
Looking at Mixpanel JQL’s product page, they do not seem to be a big fan of SQL. As a decade long SQL user, I’d like to offer an alternate perspective.
SQL: The Good Parts
Let’s go over Mixpanel’s criticisms against SQL:
- Meant for rigid schemas on traditional relational databases: This is a common source of confusion. SQL is just an interface and can work with both relational and non-relational data stores. Presto is arguably the best counterexample: Originally designed and open-sourced at Facebook, Presto can be plugged into a variety of storage systems (Treasure Data has adopted Presto as its main SQL engine for this very reason since our storage system is scheme-on-read).
- Difficult to manipulate and transform the data: Maybe for developers, but definitely not for data analysts who typically have a wealth of experience writing SQL. This is why analytics tools like Segment, Amplitude and Google Analytics all offer SQL access, Teradata is worth 3 billion dollars and data analysts love Amazon Redshift. To be sure, some operations are unwieldy (pivoting/unpivoting, for example), but overall, SQL is a solid language for data manipulation and transformation.
- Complex queries unwieldy to read and compose: This used to be true. Subqueries can lead to a heavily nested query that’s difficult to parse. However, today’s modern SQL engines like PostgreSQL, Redshift and Presto lets the user break down a complex query into manageable parts with the WITH clause.
- Limited flexibility due to query functions available in SQL: Again, this is false. SQL comes with a wide range of functions and provide ways for the user to define their own functions. For example, there’s 246 functions for Presto and more are added in each release. Furthermore, all SQL engines support User Defined Functions (UDFs) so that the user can add their own custom function as well.
Three Things to Think About Mixpanel JQL
On the other hand, JQL has a lot to be desired as a query language for data analysts. Sure, many frontend developers might be familiar with JavaScript and find the MapReduce-like API futuristically cool. But don’t forget that it’s data analysts, not JavaScript ninjas, who needs advanced analysis capabilities. My main criticisms of JQL are:
- It’s JavaScript. As a former web developer, I’ve wrangled with enough JavaScript to say that it’s a bad language for data analysis. Its quirky, counter-intuitive behavior trips up the beginners and makes debugging unnecessarily hard. Yes, JavaScript is the most popular programming language…among developers to write software. It should not be abused for data analysis because there are alternate languages designed for data analysis such as R, Python (Pandas), Matlab, etc.
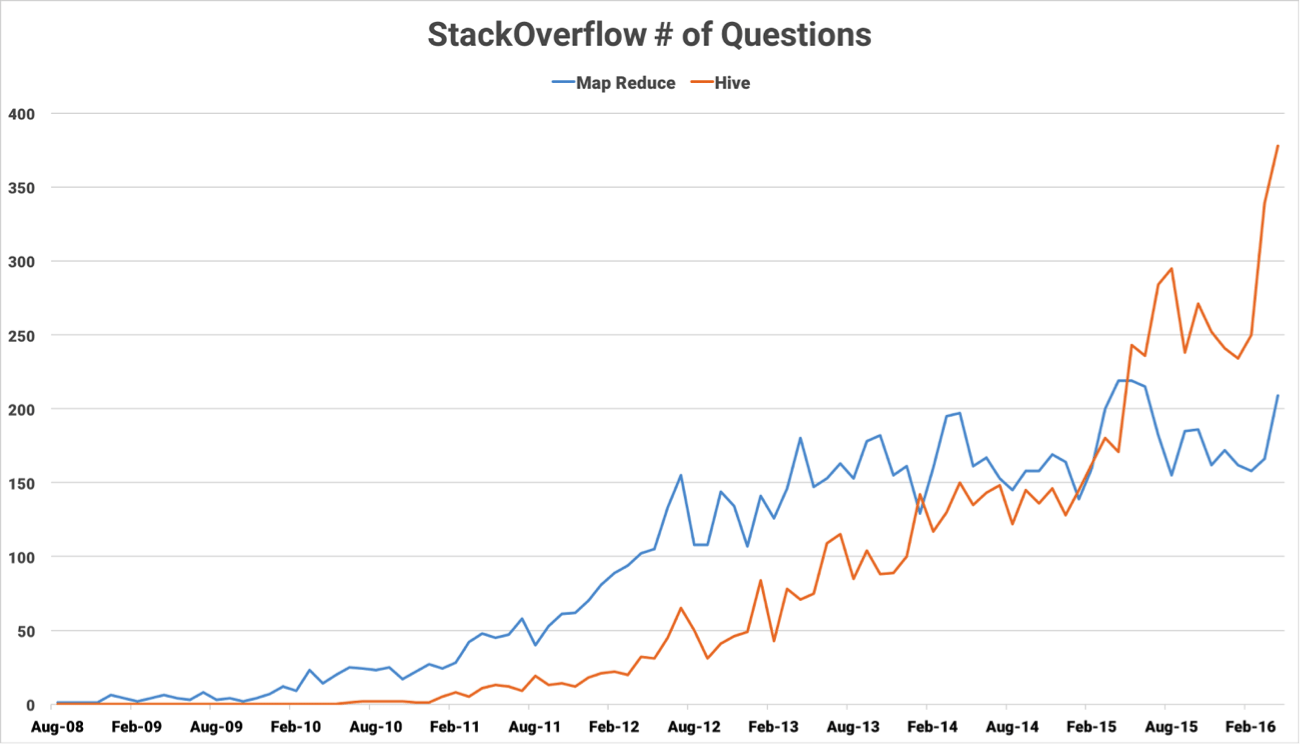
- MapReduce isn’t intuitive. At the core of JQL is MapReduce, a computing paradigm popularized by Google and Hadoop to process large data in parallel. MapReduce is a powerful concept but isn’t the most intuitive one to learn. In fact, MapReduce was so hard to write for data analysts that Facebook created Hive, the first SQL-on-Hadoop engine that translates SQL into MapReduce. And the data community at large seems to agree, as you can see from questions asked on StackOverflow:

- Vendor Lock-in. To Mixpanel’s credit, they have improved their export API quite a bit over the years, so much that we could build a data connector around it. That said, it’s dangerous to build your analytics pipeline on a proprietary domain specific language (DSL) because it makes it harder for you to move your workloads since your future staff must learn JQL just to migrate queries. SQL, on the other hand, has well-documented standards and is supported across many databases. Yes, there’s some vendor-specific features, but your data analysts can pick up these differences quickly because they are all SQL after all.
Looking Ahead: Own Your Analytics Workload
My guess is that Mixpanel had to respond to the increasing demand from their customers to run more sophisticated analysis against their data housed in Mixpanel. While I do not know for sure, it’s likely that JQL has been their internal query API all along, and they decided to open it up to their customers.
And that’s a good thing. Greater flexibility in an analytics tool is always welcomed as it enables data analysts to ask deeper, meaningful questions.
The question is how. I wish Mixpanel embraced SQL and implemented it against their storage system -even if it would have taken them longer- as it would have empowered a far greater number of data analysts to do their jobs better without a vendor lock-in.