Distributed Logging Architecture in the Container Era
Distributed Logging Architecture in the Container Era
Distributed Logging Architecture in the Container Era
TL;DR: Containers and Microservices are great, but they cause big problems with logging. You should do what Docker does: Use Fluentd. Also, if you need scale and stability, we offer Fluentd Enterprise.
Microservices and Macroproblems
Modern tech enterprise is all about microservices and, increasingly, containers. Microservices are essential in a world in which services need to support a multitude of platforms and applications. Containers, like Docker, allow much more efficient resource utilization, better isolation, and greater portability than their closest cousins, Virtual Machines, making them ideal for microservices.
But microservices and containers create their own problems. Consider a modern microservice architecture compared to its unfashionable ancestor, monolithic architecture.

Monolithic architecture may not have the virtues of scalability and flexibility, but it does have unity. To see why this is important, consider the different kinds of log data you might need to collect and aggregate, depending on your business needs. You might want to know what page your website users visited most frequently, or what buttons and ads they clicked on. You might want to compare this with sales data gathered from your mobile app, or game data if you’re a game maker. You might also want to collect operations logs from your customers’ phones, or sensor data. If your internal teams are doing funnel analysis or event impact analysis, you might need to compare these computed results with historical data. IoT data, SaaS data, public data… the list goes on and on.
The data produced by a monolithic architecture, theoretically, is easy to track. Since the system is centralized by definition, the logs it produces can all be formatted with the same schema. Microservices, as we know, are not like this. Logs for different services have their own schema, or no schema at all! Because of this, simply ingesting logs from different services and getting them into a readable format is a hard data infrastructure problem to solve.
In a containerized world, we must think differently about logging.
This is all before we start talking about containers. Containerization, as we’ve said, is a boon for microservice-based services because it’s efficient. Containers use far fewer resources than VMs — much less bare metal servers. They can be very close to their clients, increasing the speed of operations. And since they’re walled off from each other, the problem of dependencies is reduced (if not completely eliminated).
But the things that make containers so great for microservices cause more problems with logging and data aggregation. Traditionally, logs are tagged with the IP address of the server they came from. This needn’t be the case with containers, severing the fixed mapping between servers and roles. Another problem is with storage of the log files. Containers are immutable and disposable, so logs stored in the container would go away when the container instance goes away. You can store them on the host server, but you might have multiple containers and services running on the same host server. What happens when the server runs out of storage? And how should we go fetch these logs? Use service discovery software, like Consul? Great, another component to install. (Eye roll.) Or maybe we should use rsync, or ssh and tail. So now we need to make sure our favored tool is installed on all our containers…
Breaking the Log Jam: Intelligent Data Infrastructure
There’s no getting around it. In a containerized microservices world, we must think differently about logging.
Logs should be:
- Labeled and parsed at the source, and
- Pushed to their destination as soon as possible
Let’s take a look at how this works.
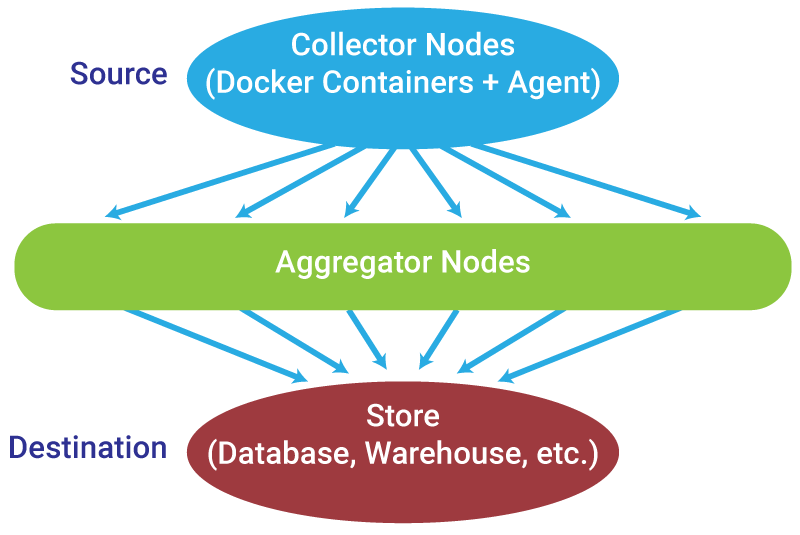
As mentioned earlier, logs from different sources can come in a variety of structured or unstructured formats. Processing raw logs is a data analytics nightmare. Collector Nodes solve this problem by converting the raw logs into structured data, i.e. key-value pairs in JSON, MessagePack, or some other standard format.
The Collector Node ‘agent’, which lives on the container, then forwards the structured data in real-time (or micro-batches) to an Aggregator Node. The job of the Aggregator Node is to combine multiple smaller streams into a single data stream that’s easier to process and ingest into the Store, where it’s persisted for future consumption.
What I’ve just described is a Data Infrastructure. Not everyone is accustomed to the idea their data needs an infrastructure, but in the Containerized Microservices world, there is no way around it.
There are a few requirements that need to be considered in order to make our data infrastructure scalable and resilient.
- Network Traffic. With all these nodes shuttling data back and forth, we need a “traffic cop” to make sure we don’t overload our network and/or lose data.
- CPU Load. Parsing data at the source and formatting it on the aggregator is CPU-intensive. Again, we need a system to manage these resources so we don’t overload our CPUs.
- Redundancy. Resiliency requires redundancy. We need to make our aggregators redundant in order to guard against data loss in case of a node failure.
- Controlling Delay. There’s no way to avoid some amount of latency in the system. If we can’t get rid of it altogether, we need to control the delay so that we know when we’ll know what’s happening in our systems.
Now that we’ve gone over the requirements, let’s look at some different aggregation patterns in service architecture.
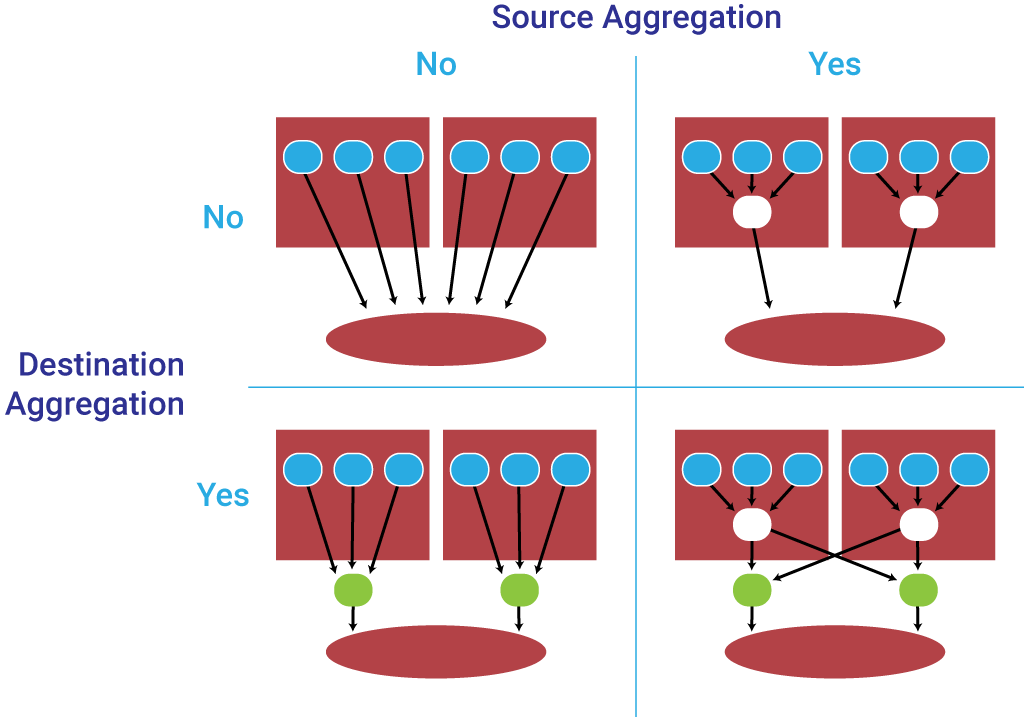
Source-Side Aggregation Patterns
The first question is whether we should aggregate at the source of the data—on the service side. The answer is a matter of tradeoffs.
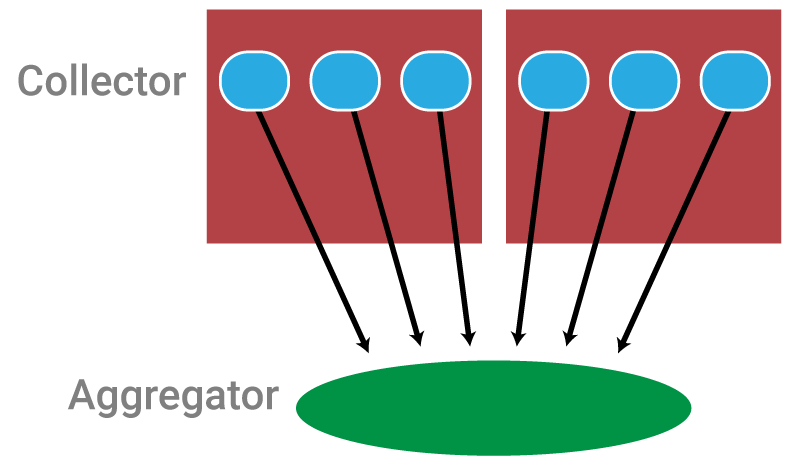
The big benefit of a service aggregation framework without source aggregation is simplicity. But the simplicity comes at a cost:
- Fixed aggregator (endpoint) address. If you change the address of your aggregator, you’ve got to reconfigure each individual collector.
- Many network connections. Remember when we said we need to be careful not to overload our network? This is how network overloads happen. Aggregating our data on the source side is much, much more network-efficient than aggregating it on the destination side — leading to fewer sockets and data streams for the network to support.
- High load in aggregator. Not only does source-side aggregation result in high network traffic, it can overload the CPU in the aggregator, resulting in data loss.
Now let’s look at the tradeoffs for source-side aggregation.
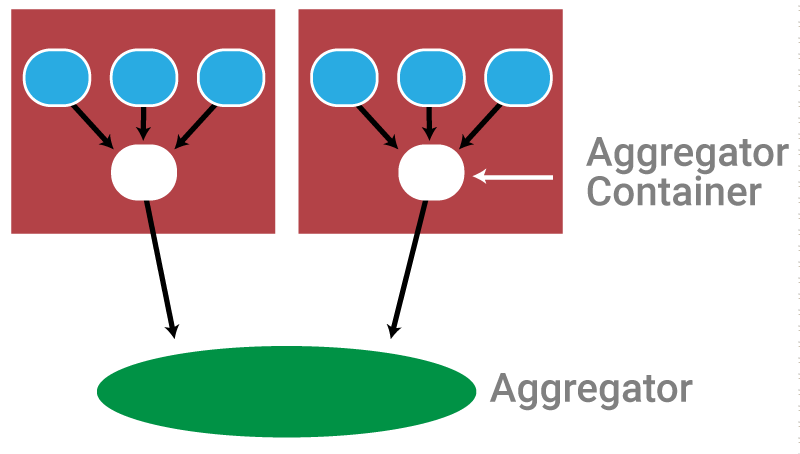
Aggregating on the source has one downside: It’s a bit more resource-intensive. It requires an extra container on each host. But this extra resource brings several benefits:
- Fewer connections. Fewer connections means less network traffic.
- Lower aggregator load. Since this resource cost is spread out over your entire data infrastructure, you have far less chance of overloading any individual aggregator, resulting in less chance of data loss.
- Less configuration in containers. Since the aggregator address for each collector is “localhost”, configuration is drastically simplified. The destination address only needs to be specified in one node—the local aggregate container.
- Highly flexible configuration. This simplified configuration makes your data infrastructure highly “modular”. You can swap services in and out to your heart’s content.
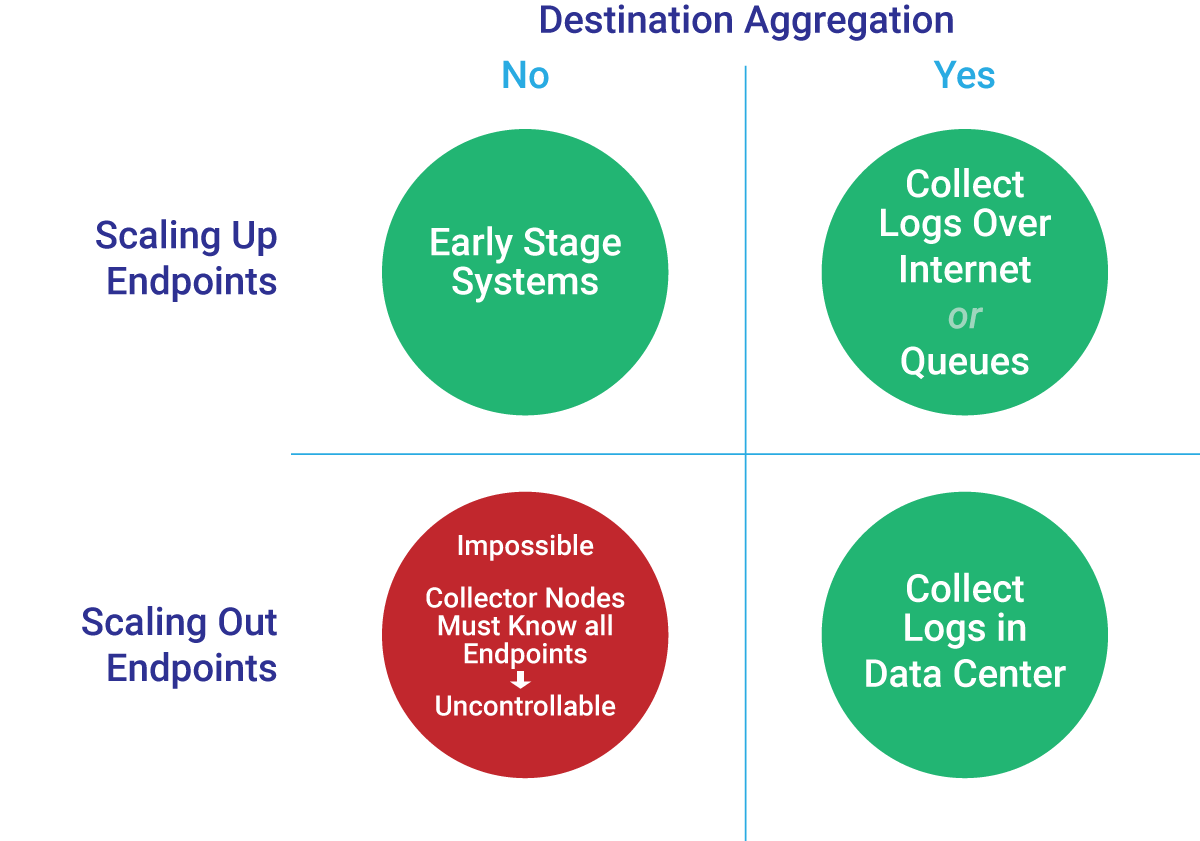
Destination-Side Aggregation Patterns
Regardless of whether we aggregate on the Source side, we can also elect to have separate aggregators on the Destination side. Whether we should do this is, again, a matter of tradeoffs. Avoiding Destination Aggregation limits the number of nodes, resulting in a much simpler configuration.
Source-Only Aggregation
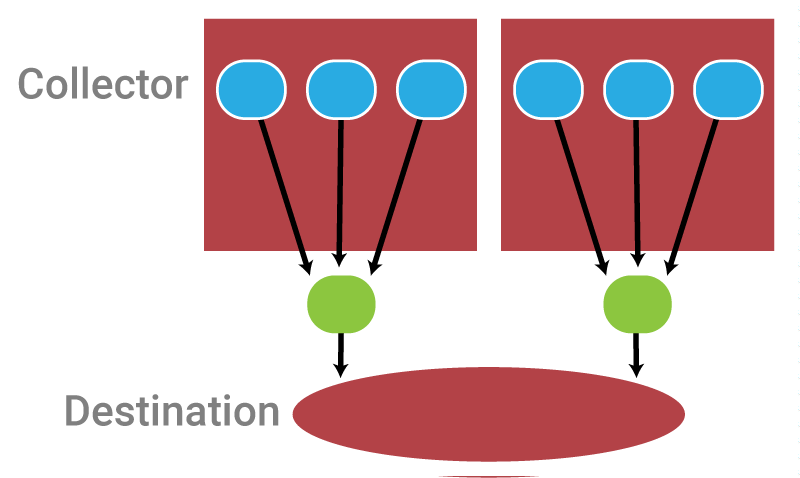
But, just as on the Source side, avoiding aggregation on the Destination side comes with costs:
- A change on the Destination side affects the Source side. This is the same configuration problem we saw when we didn’t have aggregators on the Source side. If the Destination address changes, all the aggregators on the Source have to be reconfigured.
- Worse performance. Having no aggregators on the Destination side results in many concurrent connections and write requests being made to our Storage system. Depending on which one you use, this almost always results in a major performance impact. In fact, it’s the part of the system that most often breaks at scale, bringing even the most robust infrastructures to their knees.
Source and Destination Aggregation
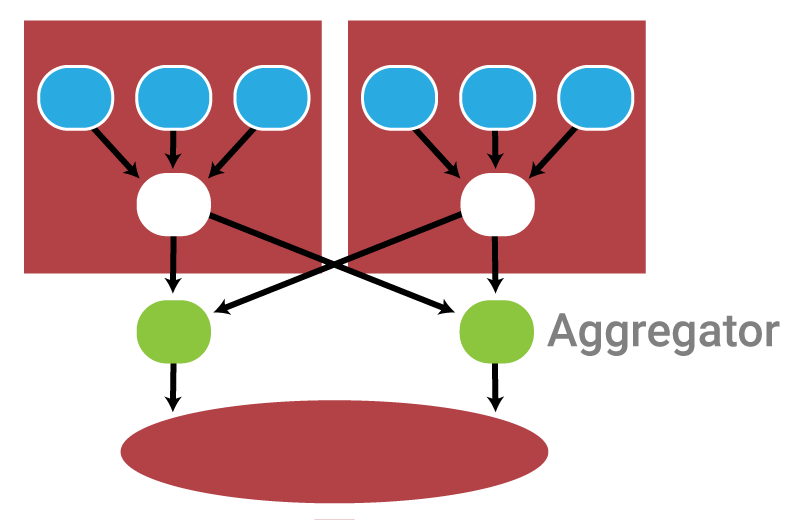
The optimal configuration is to have aggregation on both the Source and the Destination side. Again, the tradeoff is that we end up with more nodes and a slightly more complicated configuration up front. But the benefits are clear:
- Destination side changes don’t affect the Source side. This results in far less overall maintenance.
- Better performance. With separate aggregators on the Source side, we can fine-tune the aggregators and have fewer write requests on the Store, allowing us to use standard databases with fewer performance and scaling issues.
Redundancy
Another major benefit of Source side aggregation is fault tolerance. In the real world, servers sometimes go down. The constant, heavy load of processing the service log generated in a large system of microservices makes server crashes more likely. When this happens, events that occur during the downtime can be lost forever. If your system stays down long enough, even your source-side buffers (if you are using a logging platform with source-side buffers—more on that in a minute) will overflow and result in permanent data loss.
Destination side aggregation improves fault tolerance by adding redundancy. By providing a final layer between containers and databases, identical copies of your data can be sent to multiple aggregators, without overwhelming your database with concurrent connections.
Scaling Patterns
Load balancing is another important data infrastructure consideration. There are a thousand ways to handle load balancing, but the important factor we’re concerned with here is the tradeoff between scaling up, i.e. using a single HTTP/TCP load balancer which handles scale with a huge queue and an army of workers, or scaling out, where load balancing is distributed across many client aggregator nodes, in round robin fashion, and scale is managed by simply adding more aggregators.
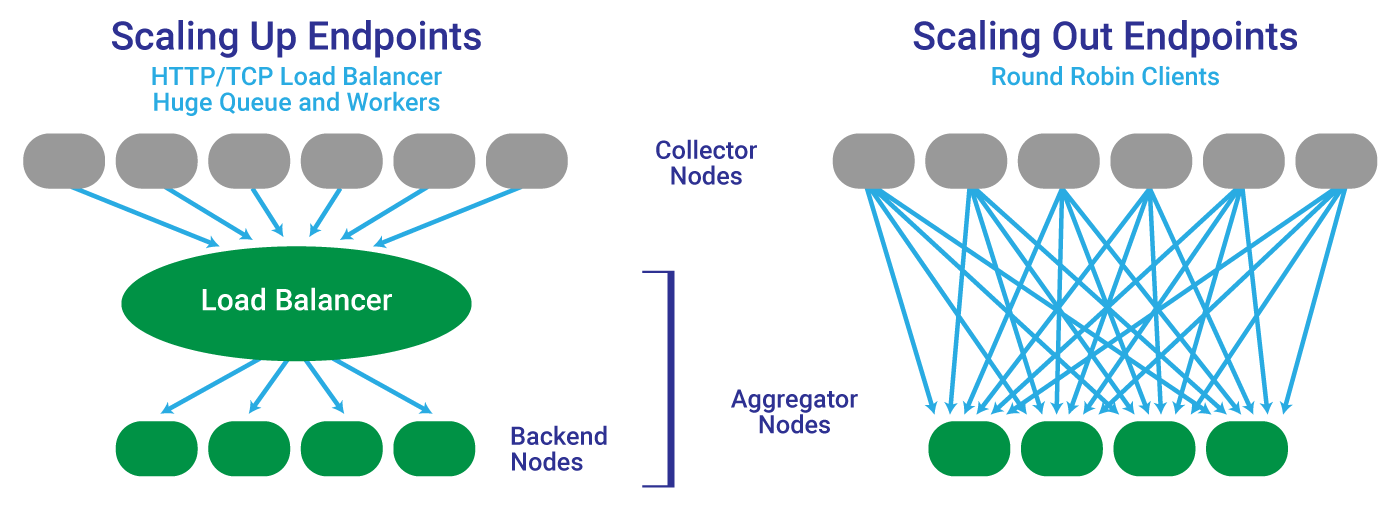
Which type of load balancing is best? Again, it depends. The approach you use should be determined by the size of your system, and whether it uses Destination-side aggregation.
Scaling up is slightly simpler than scaling out, at least in concept. Because of this, it can be appropriate for startups. But there limits to scaling up against which companies tend to smash at the worst possible time. Don’t you hate it when your service scales to 5 billion events per day and suddenly starts crashing every time it has to do garbage collection?
Scaling out is more complex, but offers (theoretically) infinite capacity. You can always add more aggregator nodes.
Lock and Key: Docker + Fluentd
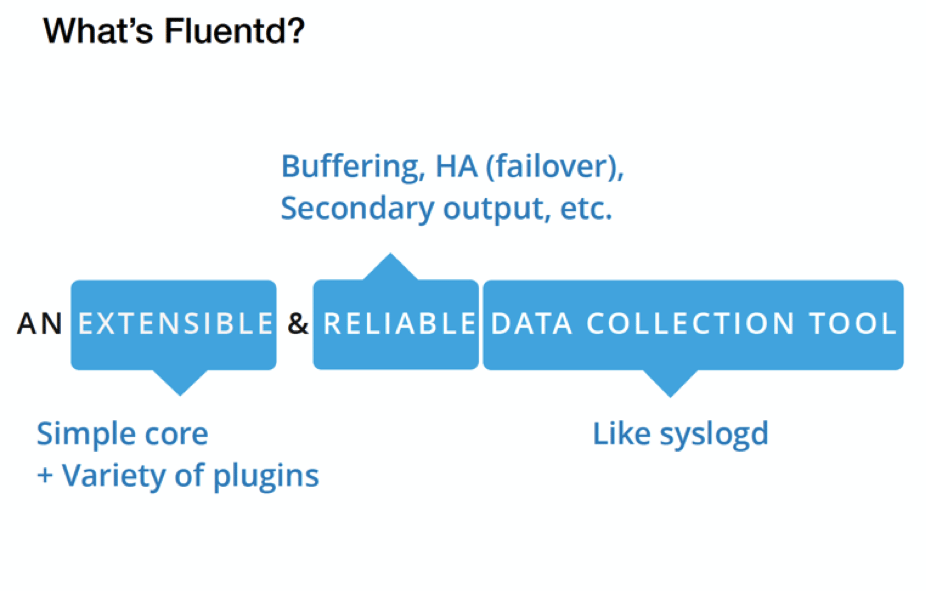
The need for a unified logging layer for microservices led Sadayuki Furuhashi, Treasure Data’s Chief Architect, to develop and open-source the Fluentd framework. Fluentd is a data collection system—a daemon, like syslogd, that listens for messages from services and routes them in various ways. But unlike syslogd, Fluentd was built from the ground up to unify log sources from microservices, so they can be used efficiently for production and analytics. The same performant code can be used in both Collector or Aggregator modes with a single tweak to configuration, making it extremely easy to deploy across an entire system.
Because Fluentd is natively supported on Docker Machine, all container logs can be collected without running any “agent” inside individual containers. Just spin up Docker containers with “–log-driver=fluentd” option, and make sure either the host machine or designated “logging” containers run Fluentd. This approach ensures that most containers can run “lean” because no logging agent needs to be installed at source containers.
Fluentd’s light weight and extensibility make it suitable for aggregating logs on both the source and destination sides, in either a “scaling up” or “scaling out” configuration. Again, which flavor is best for you depends on your present setup and your future needs. Let’s look at each in turn.
Simple Forwarding + Scaling Up
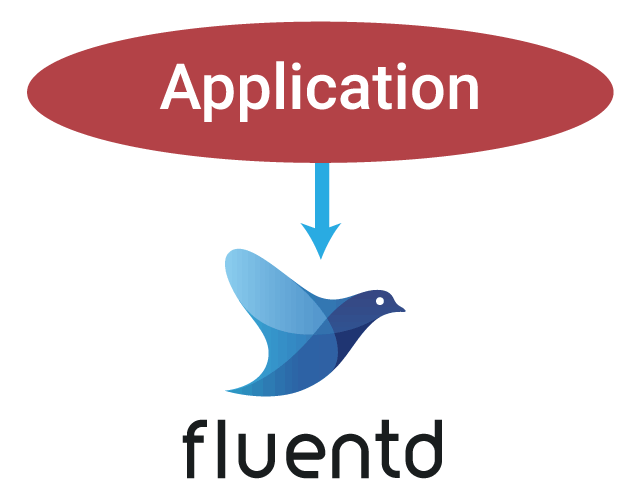
For easy setup, it’s hard to beat the simplicity of including a few lines of configuration code from the Fluentd logger library in your app and instantly enabling direct log forwarding with a single Fluentd instance per container. Because it’s nearly effortless, this can be a great boon to fledgling startups, which usually have a small number of services and data volumes low enough to store in a standard MySQL database with a few concurrent connections.
But at the risk of beating a seriously dead horse, there are limits to how much a system like this can scale. What if your startup really takes off? Depending on how data-driven your business is, you might want to put in the implementation effort up front (or consider outsourcing the problem with a managed data infrastructure stack) to avoid panic attacks later on.
Source Aggregation + Scaling Up

Another possible configuration is to aggregate on the source with Fluentd, and send the aggregated logs to a NoSQL data store using one of Fluentd’s 400+ community contributed plugins. We’ll look at Elasticsearch for this example, because it’s popular. This configuration (using Kibana for visualization), called the EFK stack, is what e.g. Kubernetes runs on. It’s reasonably straightforward, and it works great for medium data volumes. Usually.
A caveat with Elasticsearch: While being a great platform for search, it is less than optimal as a central component of your data infrastructure. This is especially true when you’re trying to load high volumes of important data. At production scale, Elasticsearch has been shown to have critical ingestion problems, including split brain, that result in data loss. In the EFK configuration, since Fluentd is aggregating on the source and not the destination, there’s nothing it can do if the store drops data.
For production-scale analytics, you might consider a more fault-tolerant platform, such as Hadoop or Cassandra — which are both optimized for high volume write loads.
Source/Destination Aggregation + Scaling Out
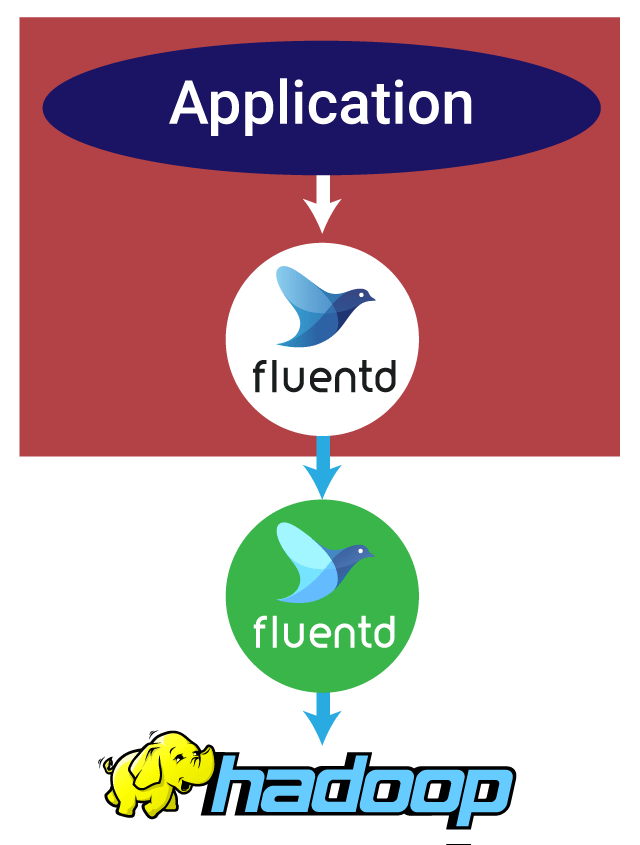
If you need to process massive amounts of complex data, your best bet is to set up both source and destination side aggregation nodes, leveraging the various configuration modes of Fluentd. With the Fluentd logging driver that comes bundled with Docker, your application can just write its logs to STDOUT. Docker will automatically forward them to the Fluentd instance at localhost, which in turn aggregates and forwards them on to destination-side Fluentd aggregators via TCP.
This is where the power and flexibility of Fluentd really comes into its own. In this architecture, Fluentd, by default, enables round-robin load balancing with automatic failover. This lends itself to scale-out architecture because each new node is load-balanced by the downstream instance feeding it. Additionally, the built-in buffer architecture gives it an automatic fail-safe against data loss at every stage of the transfer process. It even includes automatic corruption detection (which initiates upload retries until the complete dataset is transferred), as well as a deduplication API.
What configuration is right for you?
It depends on your budget and how fast you must move. Are you a resource-strapped startup processing small amounts of data? You may be able to get away with forwarding straight from your source into a single node MySQL database. If your needs are more moderate without a strong need for fail safe data capture, the EFK stack may suffice.
As organizations of all sizes become more data-driven, however, it’s worth taking the time up front to think through your long-term goals. Do you need to make sure your data pipeline won’t choke when you start processing billions of events per day? Do you want maximum extensibility for whatever data sources you may want to add in the future? Then you may want to consider implementing both source and destination aggregation up front. Your future self (and colleagues) will thank you when your data volumes start exploding.
Whatever your configuration, the simplicity, reliability and extensibility of Fluentd make it a great choice for data forwarding and aggregation. And the fact that it comes built-in with Docker makes it a no-brainer for any microservices-based system.
If you need maximum future scalability and don’t have the resources to implement it today, or want to minimize time spent on maintenance in the future, you might consider Fluentd Enterprise Support from Treasure Data. This enterprise-ready service comes with 24/7 security, monitoring, and maintenance, as well as world-class support from the team who wrote the framework.
If you want a plug-and-play data stack to outsource management of your entire analytics system, consider our fully-managed collection, storage, and processing system at Treasure Data.
Happy Logging!
Thanks to Satoshi “Moris” Tagomori, on whose LinuxCon Japan presentation this blog post is based!