Use AI to Cleanse Salesforce Job Title Data in Treasure Data
Use AI to Cleanse Salesforce Job Title Data in Treasure Data
Use AI to Cleanse Salesforce Job Title Data in Treasure Data
Bring up the word “AI” and people think of science fiction, of extraordinary near-magical feats of advanced data processing. But some of the most remarkable displays of AI power in marketing and business operations are involved in doing seemingly mundane things. An example came up recently when using Treasure Data to analyze customer data in Salesforce.
When we humans read a list of job titles, we have no problem understanding that “Vice President of Product Marketing,” “VP Pct. Mktg.” and “Prod. Mkt VP” are the same. But if we want these different phrases to be treated the same by a computer, we first have to do a process called normalization. This turns out to be an extremely challenging real-world example of using Treasure Machine Learning (ML) to great result. Let’s take a look at how it works.
A Job Title Jumble
Take a look at this customer record from Salesforce:
| name | company | country | address | title | phone | |
|---|---|---|---|---|---|---|
| John Doe | Company X | US | 000 MAIN ST SEATTLE WA 99999 | VP Marketing | john@company_x.com | (555)555-5555 |
Notice that most of the attributes except title follow a more or less specific, standardized format. Analyzing such formatted data is relatively easy both for humans and machines. Title, however, is completely human-generated; depending on the person who entered the title, there are numerous possible patterns of its value:
- VP of Marketing
- Eng. Mng.
- Marketing Manager
- Software Engineer and Entrepreneur
- Founder and CTO
- Chief Technology Officer
- …
This is bad. Why? Because the machine needs to be able to understand job titles in order, for instance, to find similar contacts and create customer segments. How can the computer tell the difference between:
- “VP of Marketing” vs. “Marketing Manager”
- “Eng.” vs. “Engineer”
- “Mng.” vs. “Manager”
- “Engineer” vs. “Engineering”
- “CTO” vs. “Chief Technology Officer”
- …?
Handling this text information is not trivial for AI. Thankfully, we have a powerful tool to help us out: Treasure Machine Learning.
AI solves a wide variety of real-world problems, but there’s often a lot of tedious preprocessing that needs to be done first. Treasure Data provides a slew of end-to-end solution templates that take the sting out of gathering and preprocessing your data so you can get to the fun stuff, fast.
From Preprocessing to Prediction: Treasure Workflow
Since data is continuously generated as time passes, AI-based analytic systems need to be automated. This is another great strength of Treasure Data: Treasure Workflow, our state-of-the-art data automation system, enables you to easily create and schedule end-to-end data processing flow from preprocessing to prediction.
Here’s what our SFDC contact data analysis workflow looks like:
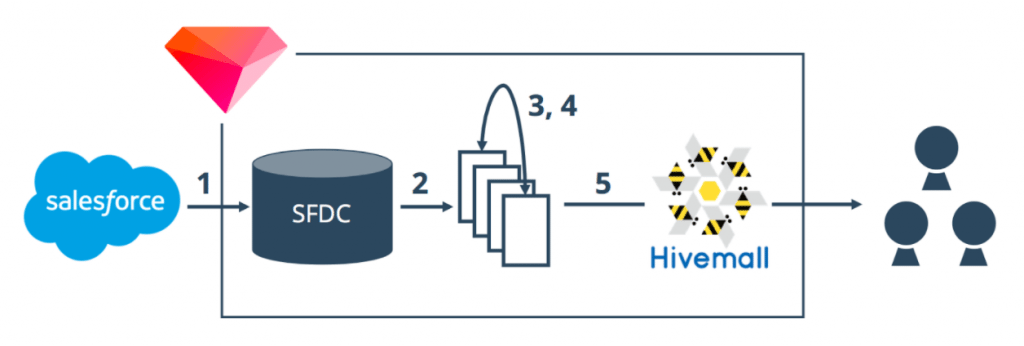
- Import SFDC raw data to Treasure Data
- Extract partial data into auxiliary tables
- Transform job titles into AI-friendly format
- Integrate transformed job titles with other attributes
- Launch AI in our Treasure ML service, and find out our potential customers for sales team
Let’s unpack step #3 and find out how we transformed those unhandy job titles.
Job Title Transformation at Treasure Data
Our goal is to find role and job categories for each job title. More concretely, here’s what we want the input and output to look like:
Input:
| id | title |
|---|---|
| 1 | VP of Marketing |
| 2 | Eng. Mng. |
| 3 | Marketing Manager |
| 4 | Software Engineer and Entrepreneur |
| 5 | Founder and CTO |
| 6 | Chief Technology Officer |
| … | … |
Output:
| id | category: role | category: job |
|---|---|---|
| 1 | executive | marketing |
| 2 | manager | engineering |
| 3 | manager | marketing |
| 4 | entrepreneur | engineering |
| 5 | executive | engineering |
| 6 | executive | engineering |
| … | … | … |
Fortunately, the number of possible categories is limited. That means we can readily incorporate the title categories into further analysis.
In order to map job titles to the categories, our workflow undergoes two sub-steps.
Step 1: Normalize and categorize job titles
The first thing our workflow needs to do is to create a title-category mapping table. Here are the steps:
- Normalize the title texts based on a predefined set of rules
- Remove meaningless words/characters
- of, and, & …
- Expand clipped words
- Mng., CEO, VP, … to Manager, Chief Executive Officer, Vice President, …
- Convert to lower case
- Manager and manager should be treated exactly the same way
- Remove meaningless words/characters
- Categorize the normalized titles
- role: all Chief XXX Officers should be in the same role category “executive”
- job: both VP of Engineering and Software Engineer are in the same job category “engineering”
- Create an intermediate title-category mapping table
Here’s what the mapping looks like:
| (original) title | category: role | category: job |
|---|---|---|
| CEO | executive | marketing |
| VP of Engineering | manager | engineering |
| Software Engineer | manager | marketing |
| Sales Manager | entrepreneur | engineering |
| Co-founder and COO | executive | engineering |
| CEO | executive | engineering |
| … | … | … |
Step 2: Estimate Category of New Contacts’ Job Title
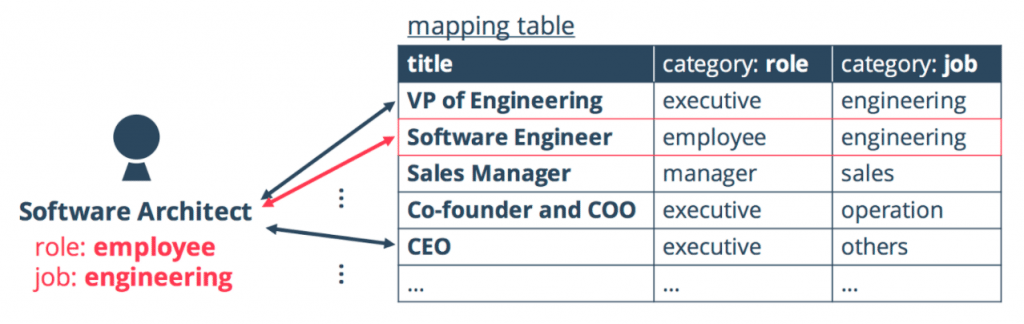
Once the title-category mapping table has been created, for new contacts, our workflow tries to estimate the category of their title. This step compares the difference of texts based on a well-know scientific technique called Levenshtein distance[1] (isn’t that fun to say?).
For example, if a title of new contact is “Software Architect”, our AI looks up the mapping table and picks up single mapping for the most similar title, e.g. “Software Engineer.” As a result, we can directly use the categories associated with “Software Engineer” as estimated categories of a new title named “Software Architect.”
Neat, huh?
What’s next?
Although preprocessing (i.e. job title transformation) is actually one of the most challenging parts of our data analytic workflow, now that it’s done it opens the way for all sorts of tantalizing possibilities:
- Create micro-segments of target accounts for account-based marketing (ABM)
- Traverse the decision hierarchy and find the right influencers to accelerate your sales cycle
- Reverse-engineer attribution by job title in order to find out what content is most relevant to your most important customers
All of this is made possible because Treasure Workflow and Treasure Machine Learning services have the capability to transform complex human-generated data into simple, easy-to-understand AI-friendly format.
If you are interested in the technical details of this article or AI-based real-world data analysis, or if you are interested in collaborating to improve and utilize our SFDC analytic system, please give us a shout!